

8 Challenges Of Building Your Own Large Language Model
Explore the top LLM challenges in building your own large language model, from managing massive datasets to high fine-tuning costs and data privacy.


In today's fast-paced digital world, large language models (LLMs) are changing how businesses work with data. However, it's not easy to make one from scratch.
In fact, a recent Gartner’s statistical analysis report found that 85% of organizations attempting to develop custom AI solutions face significant challenges in managing the complexity of these models.
Even though these AI systems are advanced, making your own model comes with its own set of problems that not many people really understand.
Have you ever considered making a language model as strong as GPT or BERT? Or why do so many businesses choose to use APIs instead of making their own?
Companies that deal with a lot of data need to use these models to simplify jobs, make their operations more efficient, and stay ahead of the competition.
But here's the catch: getting an LLM can quickly become too hard to handle if you need the right tools, information, and plans. The problems are many and expensive, like keeping track of massive records and making sure data is safe.
This blog post will discuss the eight biggest problems you'll face if you want to build your own LLM to get more control over your data and save money in the long run.
By knowing about these problems, you'll be better able to make smart choices and avoid common mistakes.
Keep reading to find out what lies ahead!
Table of Contents
- Understanding Large Language Models
- Why Build Your Own LLM?
- Understanding the Challenges with LLMs
- Benefits of Large Language Models
- Utilizing Large Language Models
- Similarity Between Generated and Human-Written Text
- Conclusion
Understanding Large Language Models
Large Language Models (LLMs) are advanced artificial intelligence systems that have been trained on massive amounts of text data to understand and generate human-like language.
These models have the capability to generate coherent and contextually relevant text, making them valuable tools for various natural language processing tasks, including text generation, translation, summarization, question answering, and more.
LLMs are built using deep learning architectures, typically based on neural networks, and they consist of numerous layers of interconnected nodes that process and analyze linguistic patterns in the input data.
These models are capable of learning intricate relationships between words, phrases, and sentences, allowing them to produce high-quality language output.
The training process for LLMs involves exposing the model to vast amounts of text from diverse sources, such as books, articles, websites, and other textual content.
The model learns to predict the next word or sequence of words in a given context, thereby developing an understanding of grammar, syntax, semantics, and even nuanced language usage.
Prominent examples of LLMs include GPT-2, GPT-3, and GPT-4, developed by OpenAI, as well as BERT and RoBERTa from Google.
These models have achieved impressive performance across a wide range of language-related tasks and have sparked significant interest and research in the field of natural language processing.
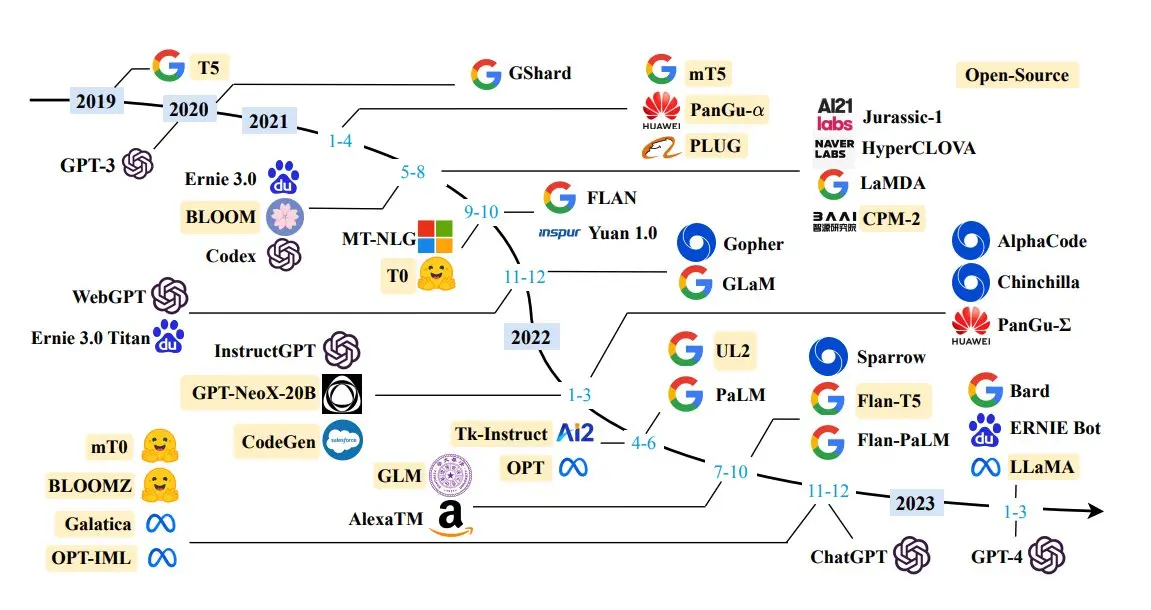
Figure: Examples of LLM
Why Build your own LLM?
Creating your own Large Language Model (LLM) as opposed to utilizing an API from an external provider like OpenAI offers numerous benefits, particularly concerning utilization, expenses, personalization, authority, confidentiality, and long-term viability.
Let's explore into these aspects in greater detail:
Personalization and Authority
When you embark on building your LLM, you wield complete command over its structure, training data, fine-tuning, and conduct.
This empowers you to tailor the model to precisely suit your application's prerequisites, guaranteeing superior alignment with your objectives.
Customized Model Behavior
You possess the capacity to fine-tune the model to generate outcomes that harmonize with your domain, industry, or specific task, a capability that fosters more precise and pertinent results.
Versatility in Usage
The ability to seamlessly incorporate the LLM within your infrastructure grants you the flexibility to employ it offline, within resource-constrained environments, or to fulfill specific deployment prerequisites.
Cost-Effectiveness
While initial expenses for development and training could be higher, long-term costs may be lower, given that you retain control over the infrastructure and can optimize for efficiency.
While using an API, Frequent API requests can translate into significant recurring expenses, especially in high-volume applications.
Data Privacy and Security
Exercising control over the data utilized for training ensures that sensitive or proprietary information remains confined within your organization.
Sustainability Over the Long Run
You assert ownership and influence over the model, even in scenarios where the API provider introduces changes or discontinues services.
Adaptation and Updates
The ability to continually train and enhance your model as new data becomes available enables you to adapt to evolving requirements and remain current.
Latency and Offline Functionality
There exists potential to optimize the model for minimal latency and offline utilization, thereby ensuring swift response times and heightened accessibility.
Understanding the challenges with LLMs
While LLMs offer remarkable capabilities, they also come with challenges and concerns. These include potential biases in the training data, inaccurate or inappropriate content generation, and ethical considerations related to their use.
As LLMs continue to evolve, researchers and practitioners work to mitigate these challenges and harness their potential for various applications, shaping the future of human-computer interaction and communication. Some of the Prominent Challenges include:
Unfathomable Datasets
Scaling up the volume of pre-training data has been a key driver in enhancing the capabilities of Large Language Models (LLMs) to handle a wide range of tasks.
However, these datasets have grown so large that manual quality checks are practically infeasible. Instead, data collection methods often rely on heuristics and filtering techniques.
This section delves into the negative implications of these heuristics and the limited understanding many model practitioners have about the data used for training.
This issue is referred to as "Unfathomable Datasets." The sheer size of modern pre-training datasets makes it nearly impossible for individuals to assess the content thoroughly.
Issues with near-duplicates in the data can harm model performance. These are challenging to detect and filter, as opposed to exact duplicates. Various methods have been proposed to address this, such as NearDup and SemDeDup.
Benchmark Data Contamination arises when the training data overlaps with the evaluation test set, leading to inflated performance metrics. Removing such overlaps is difficult, and imperfect solutions may impact model quality.
Personally Identifiable Information (PII) has been found within pre-training data, causing privacy breaches during prompting. Addressing this concern is crucial.
Pre-Training Domain Mixtures, which involve combining datasets from different sources, have been advocated for diversity, but finding the right mixture remains an open question.
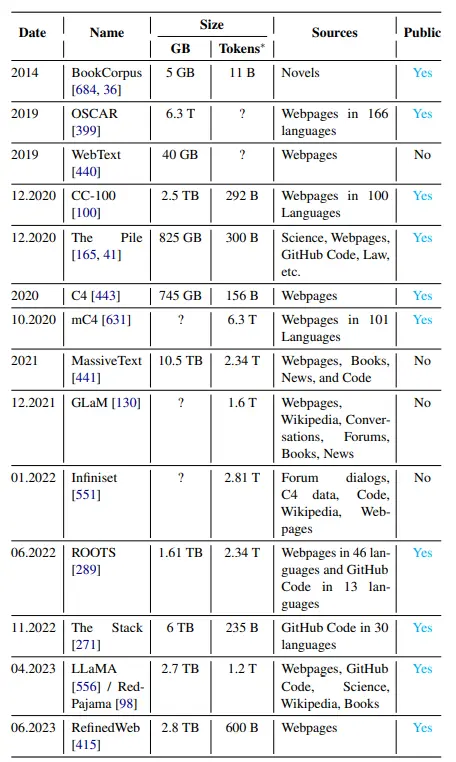
Figure: Selected Pre-training Datasets
Fine-Tuning Task Mixtures involve training models on multiple tasks simultaneously, leading to generalization improvements, but determining optimal mixtures and balance between tasks is a challenge.
Tokenizer-Reliance
Tokenization refers to the process of dividing a sequence of text into smaller units called tokens, which are then fed into a model. One common approach is subword tokenization, where words are broken into smaller subwords or WordPieces.
The aim is to effectively handle rare words while keeping the number of tokens manageable for computational efficiency. Subword tokenizers are trained without supervision to create a vocabulary and merge rules for efficient data encoding.
However, tokenization has drawbacks, including language-dependent token counts that can lead to unfair pricing policies for API language models.
Glitch tokens can result from discrepancies between the tokenizer and model training data, causing unexpected behavior.
Tokenization techniques that work well for languages like Chinese remain challenging, and current methods favor languages with shared scripts, leaving low-resource languages at a disadvantage.
Tokenizers introduce challenges like:
- Computational overhead
- Language dependence
- Vocabulary size limitations
- Information loss
- Reduced human interpretability.
Subword-level inputs are prevalent, striking a balance between vocabulary size and sequence length. Subword tokenization methods like Byte-Pair Encoding (BPE) and WordPiece are commonly used.
Byte-level inputs provide an alternative to subword tokenization, where UTF-8 bytes represent characters. Models like Charformer and Canine operate without tokenization, and methods like image-based encoding are explored to handle byte-level inputs.
Despite its advantages, tokenization can sometimes result in information loss, particularly for languages like Chinese where word boundaries are not clearly defined.
High Fine Tuning Overhead
Pre-training large language models (LLMs) on extensive and diverse textual data can result in models that need help to capture the unique properties of specific task-oriented datasets.
Fine-tuning is a technique used to adapt pre-trained LLMs to smaller, domain-specific datasets, enhancing their performance for particular tasks.
This approach involves further training the model using either the original language modeling objective or by adding learnable layers to the pre-trained model's output representations to align them with specific downstream tasks.
However, fine-tuning entire LLMs presents challenges due to large memory requirements, making it impractical for many practitioners. Storing and loading individual fine-tuned models for each task incurs computational inefficiency.
An alternative is parameter-efficient fine-tuning (PEFT), which updates only a subset of the model parameters. Methods like Adapters and prompt-tuning achieve effective adaptation while updating a small fraction of the model's parameters.
PEFT methods like prefix-tuning and prompt-tuning prepend learnable token embeddings to inputs, enabling more efficient storage.
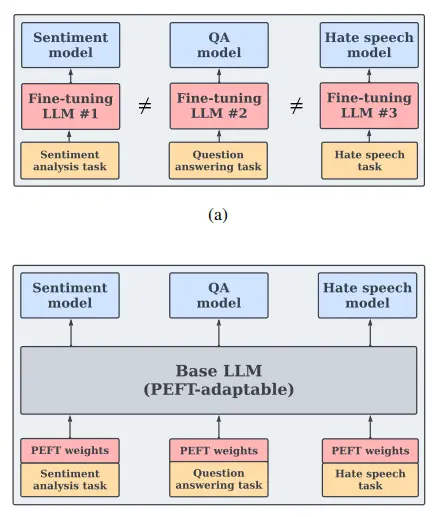
Figure: a) Vanilla fine-tuning involves updating the entire LLM to specialize it for the task. b)Parameter-efficient fine-tuning (PEFT), focuses on updating only a small subset of the LLM's parameters while keeping the base model fixed.
Research has shown that PEFT methods can achieve competitive performance with minimal training data, making them efficient for specific tasks.
Techniques like (IA)3, MeZO, LoRA, and quantized LLMs further optimize fine-tuning, reducing memory usage and computational complexity.
Despite these advancements, the time complexity of fine-tuning remains a challenge, limiting applications like personalization on smaller devices.
High Inference Latency
Pope et al. (2019) and Weng (2021) highlight two primary reasons for the high inference latencies observed in large language models (LLMs).
First, the inference process of LLMs is hindered by low parallelizability, as it operates token by token.
Second, the considerable memory footprint of LLMs is attributed to the model's size and the transient states necessary during decoding, such as attention key and value tensors.
These authors also delve into the quadratic scaling issues of attention mechanisms within Transformers.
Several techniques have been developed to address these challenges to improve LLM inference efficiency. These methods aim to reduce memory requirements, accelerate computational operations, or optimize decoding strategies.
Some notable approaches include quantization, which lowers memory usage and increases throughput by reducing the precision of weights and activations. Pruning involves removing parts of the model's weights without degrading performance.
Mixture-of-Experts architectures involve utilizing a subset of experts to process inputs, reducing inference time and communication across devices.
Cascading employs differently-sized models for various queries, and decoding strategies like speculative sampling and latency-oriented strategies enhance computational speed.
Software frameworks like DeepSpeed and Megatron-LM have been designed to facilitate the efficient training of large language models.
These frameworks leverage parallelism strategies, memory optimizations, and specialized implementations to address the computational demands of LLMs.
Moreover, libraries like vLLM and Petals provide tools for more efficient inference and collaborative fine-tuning of LLMs, respectively.
These techniques collectively aim to mitigate the computational costs associated with LLMs and improve their practical usability.
Hallucinations
The popularity of services like ChatGPT highlights the growing utilization of Large Language Models (LLMs) for everyday question-answering tasks.
Consequently, ensuring the factual accuracy of these models has become more important than ever before.
But what do you mean by hallucinations in LLMs?
However, LLMs often suffer from hallucinations, wherein they generate linguistically coherent text that contains inaccurate information.
These hallucinations can be difficult to identify due to the fluency of the text.
Figure: An illustration of GPT-4's hallucinations, as of February 6th, 2023, pertains to instances where it produces seemingly coherent yet inaccurate information.
The source content provided to the model, such as prompts or context, is considered to categorize hallucinations.
Intrinsic hallucinations involve text that contradicts the source content, while extrinsic hallucinations are generated outputs that cannot be verified or contradicted by the source.
Liu et al. attribute hallucinations in LLMs to an inherent flaw in the architecture of Transformer models. This issue is distinct from the minimalistic synthetic benchmarks used for algorithmic reasoning.
Strategies to mitigate hallucinations without altering the model architecture include supplying the LLM with relevant external sources through retrieval augmentation or adjusting decoding techniques.
How can you measure if there is hallucination in your model?
Measuring hallucinations involves datasets like Factuality Prompts, which help assess the impact of prompt accuracy on model outputs.
Various metrics, such as named-entity recognition and textual entailment, are used to measure the presence of hallucinations.
Additionally, approaches like breaking generated text into atomic facts and evaluating their support from external knowledge sources like Wikipedia are proposed.
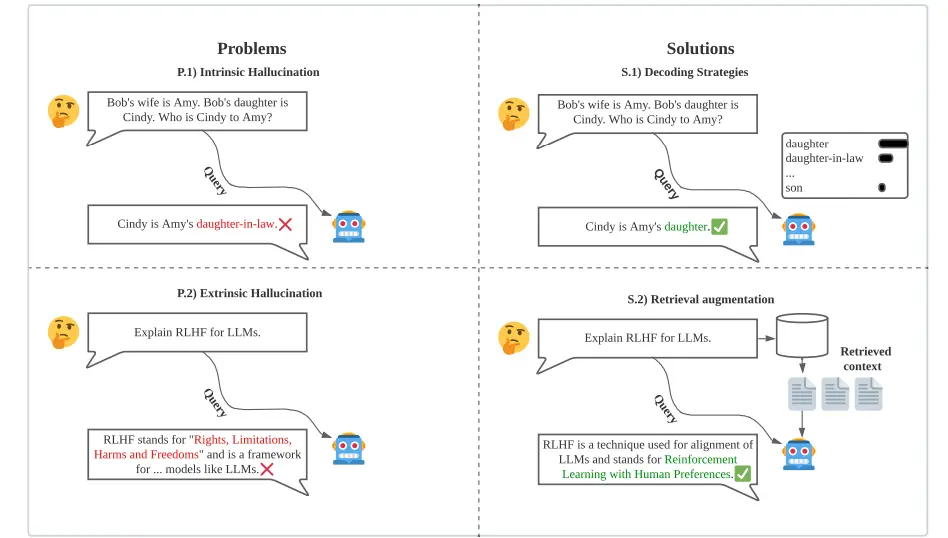
Figure: Intrinsic and Extrinsic Hallucinations
How can you reduce hallucination from your model?
Retrieval augmentation is a technique to reduce hallucinations by providing external knowledge to the model.
A retriever module retrieves relevant documents or passages, which are then combined with the initial prompt to enhance the model's understanding.
This approach aims to improve context and reduce the risk of generating inaccurate information.
However, retrieval augmentation does not always completely eliminate hallucinations. Challenges include situations where relevant documents cannot be retrieved or where retrieved information needs to be more sufficient.
Decoding strategies offer an alternative solution by refining how responses are generated during inference.
Standard decoding algorithms introduce randomness to improve text naturalness but can also lead to hallucinations.
Techniques like diverse beam search and confident decoding aim to strike a balance between generating diverse yet accurate responses.
Uncertainty-aware beam search and confident decoding methods focus on addressing hallucinations at the decoding level.
These methods incorporate uncertainty and source attention measures to improve the quality of generated responses' quality.
Outdated Knowledge
Factual information acquired during the initial training phase of a model may contain errors or become outdated over time, such as failing to account for political leadership changes.
However, retraining the model with new data is costly, and attempting to replace old facts with new ones during fine-tuning is challenging.
Current methods for editing models to update specific knowledge are limited in their effectiveness. For example, Hoelscher-Obermaier et al. found that model edits can lead to unintended associations, which restricts their practical use cases.
These methods need more precision and specificity, making updating only the necessary information without affecting unrelated parts difficult.
Two main strategies are employed to address this issue. Model editing techniques modify the model's parameters to achieve the desired behavior change.
These can be categorized into locate-then-edit methods, which identify and modify problematic model parameters, and meta-learning methods, which predict weight updates using an external model.
Another approach is to preserve model parameters while introducing changes through post-edit models or additional weights.
For instance, adapters can be added to model layers with a similarity-based mechanism to determine when to apply edits.
However, these methods need help in generalization and performance across different model architectures. They may work well only for specific types of models, such as decoder-only LLMs.
An alternative solution is retrieval-augmented language modeling, which leverages non-parametric indices of knowledge. These indices can be updated during inference to reflect the latest information.
This approach enables the model to answer questions about events or individuals that have changed since the initial training.
Lewis et al. and Izacard et al. demonstrate the effectiveness of this approach by showing that retrieval-augmented models can dynamically update their knowledge by swapping the non-parametric memory or index.
Benefits of Large Language Models
Large language models offer significant advantages to organizations, making them a valuable asset for data-intensive companies. Here are some of the key benefits of utilizing LLMs:
Advanced Natural Language Processing (NLP) Abilities
LLMs, such as GPT-3.5, bring remarkable potential to the field of natural language processing, enabling AI systems to understand and interpret text and speech much like humans.
Unlike the previous approach of employing multiple machine learning algorithms for text comprehension, LLMs simplify and enhance this process.
They empower AI-driven systems, like ChatGPT and BARD, to comprehend human language more effectively and rapidly, revolutionizing the understanding of textual data.
Enhanced Generative Capacity
The attention garnered by ChatGPT underscores its conversational prowess, a capability rooted in LLMs. These language learning models possess robust generative capabilities, analyzing vast datasets to provide valuable insights.
This aptitude augments human-machine interaction and generates precise outcomes for various prompts. ChatGPT stands as a prime example of this advancement.

Figure: Generating Images using Prompts
Improved Operational Efficiency
LLMs excel in comprehending human language, making them particularly advantageous for automating repetitive or labor-intensive tasks.
For instance, professionals in the finance sector can leverage LLMs to automate financial operations and data analysis, streamlining processes and reducing manual workload.
This enhanced efficiency through task automation contributes significantly to the widespread adoption of LLMs in various industries.
Facilitated Language Translation
Large language models facilitate seamless language translation between different languages. These models grasp the linguistic structures of distinct languages by employing deep learning algorithms like recurrent neural networks.
As a result, they enable smooth cross-cultural communication and break down language barriers, making language translation more accessible and effective.
Utilizing Large Language Models
In today's rapidly evolving technological landscape, Large Language Models (LLMs) have emerged as powerful tools for various applications in natural language processing.
These models possess the ability to generate coherent and contextually relevant text, making them invaluable assets in tasks such as text generation, summarization, translation, and more.
There are several avenues through which one can leverage the capabilities of LLMs, ranging from user-friendly API integrations to open-source implementations and even the ambitious endeavor of building a model from scratch.
Below we discuss these in detail:
API Integration
You can use APIs provided by organizations like OpenAI to easily incorporate Large Language Models (LLMs) into your applications.
These APIs allow you to send text prompts to the model and receive generated text in response. No need to worry about the technical details; documentation and examples are available.
Open Source Versions
Open-source projects such as GPT-2, GPT-Neo, and GPT-J aim to replicate the capabilities of commercial LLMs. They offer code and pre-trained models for those interested in experimenting with LLMs without the need for commercial access.
Fine-Tuning Pre-trained Models
You can start with a pre-trained LLM like GPT-3.5 and fine-tune it for your specific use case.
This is a more efficient way to adapt the model to your needs compared to building from scratch, as the model has already learned general language patterns.
Creating Your Own Model
Building an LLM from scratch is a complex endeavor that demands substantial knowledge in machine learning and natural language processing.
It involves tasks like data collection, model architecture design, and training. This route requires significant resources and expertise.
Similarity between Generated and Human-Written Text
Detecting text generated by large language models (LLMs) holds significance for several reasons, including combating the spread of misinformation, preventing plagiarism, thwarting impersonation and fraud, and maintaining the quality of future model training data.
However, the task becomes more challenging as LLMs become more fluent and capable. Approaches to Detecting LLM-Generated Text include:
Post-hoc Detectors
These methods aim to classify text as LLM-generated after it has been produced.
Various strategies have been explored, such as visualizing statistically improbable tokens, using energy-based models to differentiate real and fake text, and examining authorship attribution problems.
One approach, called "DetectGPT," leverages the curvature of the model's log probability function to identify generated passages.
Watermarking Schemes
Watermarking involves adding hidden patterns to generated text to make it detectable by algorithms. This technique modifies the text generation process by partitioning the vocabulary and sampling tokens accordingly.
Watermarking has been investigated for its effectiveness in identifying LLM-generated text, even when the text is rewritten by humans or mixed with hand-written content.
Paraphrasing Attacks
Adversaries can attempt to evade detection by rephrasing LLM-generated text to remove distinctive signatures.
Paraphrasing attacks involve rewriting the text to retain similar meaning while altering word choice or sentence structure. Such attacks can undermine existing detection methods.
Misaligned Responses
The alignment problem refers to ensuring that large language models (LLMs) behave in ways consistent with human values and objectives, avoiding unintended negative consequences.
Existing efforts to address alignment can be grouped into methods for detecting misaligned behavior and methods for aligning model behavior.
One real case scenario for the Misaligned Response of the model can be:
Imagine a social media platform that employs a language model-based system for content moderation. The goal is automatically detect and remove offensive, abusive, or inappropriate user-generated content from the platform.
However, the system occasionally needs to correct mistakes by failing to flag harmful content or incorrectly flagging benign content as offensive.
For instance, the system might let through hate speech or discriminatory language in comments or posts, which goes against the platform's commitment to providing a safe and respectful online environment.
On the other hand, the system might wrongly flag legitimate discussions on sensitive topics as offensive, suppressing free expression and users' frustration.
Figure: Misalignment of Model (ChatGPT), which gives the output.
LLMs often generate outputs that do not align well with human values, leading to unintended or harmful outcomes. To tackle this, various approaches have been explored.
- Pre-Training With Human Feedback (PHF): Incorporating human feedback during the pre-training stage is proposed as a way to improve alignment.
Different PHF approaches are compared, with "conditional training" standing out as effective. - Instruction Fine-Tuning: LLMs are fine-tuned on instructional data containing human-judged natural language instructions and responses.
Instruction-tuned (IT) LLMs often achieve superior downstream performance and generate more truthful, less toxic text. - Reinforcement Learning From Human Feedback (RLHF): RLHF involves using human-generated rewards to align LLM behavior. Models are trained to optimize for human preferences through ranking and reward-based evaluation.
- Self-Improvement: LLMs are fine-tuned on self-generated data, improving both capabilities and alignment with human values.
- Evaluation and Auditing: Thorough evaluation and auditing of LLM behavior are crucial for alignment. Red teaming, where humans create prompts to test LLM outputs, is a widely used approach.
- Biases and Toxicity: LLMs can inherit biases from training data, leading to biased outputs. Mitigation strategies include fine-tuning with human preferences or instructions, as well as the development of toolkits for debiasing models.
- Prompt Injections and Agency: LLMs can be sensitive to prompt injections, leading to unsafe behavior. Research focuses on understanding and addressing prompt-related vulnerabilities.
Conclusion
The development of Large Language Models (LLMs) has led to major breakthroughs in natural language processing, but there are still many challenges to overcome.
From dealing with massive datasets that may contain errors or biases, to managing the high costs of fine-tuning, these issues need careful attention.
LLMs also face problems like slow response times, generating incorrect information (hallucinations), and struggling to update old knowledge.
Tokenization adds complexity, and it’s becoming harder to tell the difference between human and AI-generated text.
One of the biggest challenges is making sure LLMs produce responses that align with human values.
Solving these issues will take ongoing research and responsible development. If we can address these challenges, LLMs will become even more powerful tools, transforming industries and improving everyday technology.
Now is the time for experts and innovators to come together and ensure LLMs are developed in a way that benefits everyone.
Frequently Asked Questions
1. Why Build Your Own Large Language Model?
Building your own Large Language Model (LLM) offers customization, personalization, and control over data privacy. Tailoring the model to your needs ensures better alignment with your objectives.
2. What Challenges Are Associated with Building LLMs?
Creating LLMs involves addressing issues like data quality, tokenization limitations, resource-intensive fine-tuning, potential biases, and ensuring outputs align with human values.
3. How Can LLM Challenges Be Managed?
Strategies such as pre-training with human feedback, efficient fine-tuning methods, watermarking, and robust evaluation techniques help mitigate challenges and enhance the usability of LLMs.
4. What Benefits Come with Building Your Own LLM?
Creating your LLM provides flexibility, cost-effectiveness, and control over model behavior. You can tailor it to specific tasks, optimize for efficiency, and ensure data privacy, making it a valuable asset for your organization.
5. How Can LLM Challenges Impact Real-World Applications?
Challenges in LLM development, such as biases, hallucinations, and outdated knowledge, can lead to inaccurate or misleading outputs. This can affect applications like content moderation, information dissemination, and decision-making, underscoring the importance of addressing these issues.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
