

Image Annotation: Challenges & Their Solutions


Creating a machine learning (ML) and artificial intelligence (AI) model that emulates human capabilities requires extensive training data.
The model must be trained to recognize specific objects, enabling it to make informed decisions and take appropriate actions. The datasets used for training must be meticulously categorized and labeled according to a specific use case. Companies can enhance their ML and AI implementations by utilizing high-quality data annotation services carried out by human experts.
The overarching objective is to enhance the customer experience across various applications, such as improving product recommendations, enhancing text recognition in chatbots, refining search engine results, perfecting speech recognition, advancing computer vision, and ensuring accurate image annotation.
The task of labeling data is of utmost importance, as even the slightest error in the process can lead to significant complications.
To navigate the nuances of intent and address ambiguities, businesses should equip their workforce with the necessary skills to complement and enhance ML and AI models.
Figure: Challenges and Solutions in Image Annotation
In this blog, we aim to discuss the challenges related to Image Annotation and particularly the solutions that we can take to prevent them - to an extent.
Table of Contents
- Tackling Ambiguity and Subjectivity in Annotation
- Balancing Scale and Cost in Annotation Projects
- Quality Assurance in Image Annotation: Best Practices
- Conclusion
- Frequently Asked Questions (FAQ)
Tackling Ambiguity and Subjectivity in Annotation
Teaching machine learning algorithms to recognize patterns and representations in data is vital, enabling the algorithm to generalize effectively for a given task.
However, the algorithm's performance heavily depends on the careful data curation. The quality of the data used for training these algorithms significantly influences their accuracy and effectiveness.
In the realm of machine learning, data annotation involves the organization and categorization of information to develop algorithms. Ensuring that algorithms receive precise and relevant data is a pivotal step in machine learning.
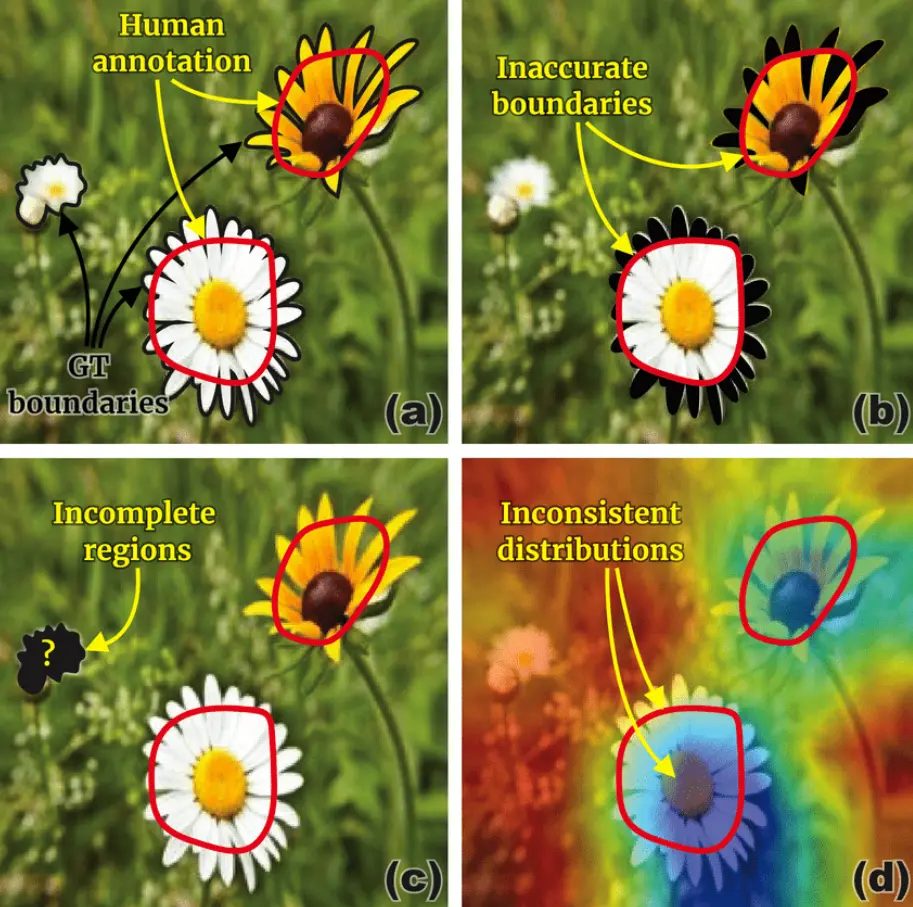
The above figure highlights the difficulties encountered in human annotation labels:
(a) human annotations are depicted using red lines, contrasting with the ground-truth boundaries displayed in black lines. (b) Errors resulting from "inaccurate boundaries" are indicated by black regions, (c) Errors arising from "incomplete regions" are represented by a black area, and (d) the disparities between the "binary" human annotation and the "continuous" explanation maps generated by the model.
Regrettably, data annotation is challenging and time-consuming, sometimes leading to errors and inconsistencies. Different annotators may interpret the same data differently, resulting in inconsistent labeling, which can negatively impact model performance and accuracy.
We can take certain measures to reduce the ambiguity in the data used.
- Establish clear guidelines
Formulate detailed instructions for annotators to ensure uniformity and minimize ambiguity. This involves providing examples of both correct and incorrect annotations and clarifying any domain-specific terminology or requirements.
2. Select appropriate annotators
Choose annotators with expertise in the domain and the necessary skills for the task. Depending on the task's complexity, additional training may be necessary to ensure a comprehensive understanding of the requirements.
3. Employ multiple annotators
Assign multiple annotators to label the same data, reducing the likelihood of human errors and biases. Subsequently, employ methods like majority voting or advanced techniques to reconcile discrepancies in annotations.
4. Implement quality control measures
Create a system to regularly assess annotation quality through periodic reviews, spot checks, or comparisons against a gold-standard dataset. Provide feedback to annotators and address any identified issues.
5. Utilize automation and AI-assisted annotation
Integrate machine learning algorithms or pre-trained models to support annotators, streamlining their workload and enhancing efficiency. This approach can identify patterns and suggest annotations, with human annotators validating and refining the results.
6. Maintain transparent communication
Foster open communication among annotators, project managers, and ML engineers to address queries, share insights, and resolve any issues. This collaboration ensures everyone is aligned with annotation expectations.
7. Iterate and refine
Continuously review and update the annotation process based on feedback, emerging insights, or alterations in project requirements. This iterative approach ensures the ongoing relevance and effectiveness of the annotation process in generating high-quality data.
Balancing Scale and Cost in Annotation Projects
The cost of image annotation projects is influenced by various factors such as intricacies, annotation types, and timelines.
Different pricing structures exist among labeling tools and service providers, providing options for project teams looking to avoid establishing their own labeling pipelines.
Regardless of the chosen approach, prioritizing annotation quality is essential as it directly impacts the ultimate performance of the model.
Further, developing image-based AI systems involves training or fine-tuning machine learning models with annotated images to create AI systems capable of accurate analysis, prediction, and generation of results.
Image annotation contributes to the overall cost of developing these AI systems. In this section, we explore factors influencing image annotation costs and emphasize the importance of considering more than just price when training and fine-tuning computer vision models.
Factors Affecting Image Annotation Costs-
- Volume: Larger projects with extensive image datasets generally incur higher annotation costs, especially if relying solely on human labelers. Active learning models can be used to automate some processes and reduce costs.
- Annotation Type: The nature of the annotation task affects costs. For instance, simpler tasks like image classification are less expensive, while more complex tasks like semantic segmentation can be costlier.
- Quality: A trained labeling workforce incurs higher costs but reduces errors, particularly in complex tasks like semantic segmentation and polygons.
- Urgency: Projects with tight deadlines will cost more, as data labeling service providers commit more labelers and increase the labeling pace while maintaining quality.
Further, overall cost is not solely dictated by project requirements but is also influenced by infrastructural and operational expenses. Two primary approaches are commonly used: in-house development of annotation tools or outsourcing to third-party labeling services.
In-House vs. Third-Party Labeling Tools
Organizations may opt for in-house development for control over security, flexibility, and annotation quality. However, this may be financially impractical for smaller companies due to high upfront costs.
Third-party labeling services simplify the annotation pipeline, providing comprehensive platforms for task assignment, automation, and review. For instance, Labellerr offers interactive features, such as ML-assisted semantic segmentation.

Figure: Labellerr - AI-Assisted Data Labelling Tool
Pricing Models of Third-Party Tools
Well, the pricing models of these tools definitely differ and have different subscription plans. To have a balance between scalability and cost, start with some Free annotation tools and then move up as per the requirements.
- Free: Some tools follow open-source or freemium models, offering basic features with potential limitations.
- Pay as you go: Charges are based on exporting annotated images, with flexibility tied to certain feature limitations.
- Subscription-based: Fixed fees grant access to labeling features, suitable for projects with consistent monthly annotation needs.
- Custom pricing: Larger enterprises opt for customized plans with bulk pricing and long-term commitments for cost savings.
Quality Assurance in Image Annotation: Best Practices
Another Common and Biggest challenge in Image Annotation is Quality Assurance. Image annotation plays a pivotal role in the training of machine learning models, as the accuracy of annotations is essential for your model's ability to correctly identify objects in images and videos.
You can refer here for a detailed description of the best practices for ensuring the Quality of annotated images.
Conclusion
Making smart computers that understand things like humans needs a lot of training data. We must carefully organize and label this data to teach our machines well. This helps in making better experiences for people in different apps.
But, there are challenges in this process. Sometimes, it's not clear how to label the data, and it can be expensive. To tackle these challenges, we use clear rules, choose the right people for labeling, have more than one person check the labels, use smart tools to make things faster, and talk openly about any issues.
Dealing with unclear situations and keeping costs in check is important. We think about how much data we have, what type of labeling we need, how good the quality should be, and how quickly we need it. Smart tools that learn as they go and use automated processes help a lot.
Another choice is deciding whether to build our own tools or use others' tools. It depends on how much control we want and how much it costs. The price plans for these tools can be free, based on usage, a fixed fee, or a custom plan for big companies.
Ensuring the labeled data is accurate is a big challenge. We follow good practices like clear rules, strict checks, and using smart tools to help. This makes sure our smart machines learn the right things.
Frequently Asked Questions (FAQ)
1. What does an image annotator do?
Accurately recognize, examine, and gather pertinent information from images and videos as instructed by the team supervisor.
2. How does image annotation differ from labeling?
Data labeling is frequently utilized in applications like sentiment analysis, text classification, and categorization. On the other hand, data annotation, known for offering more comprehensive context, is commonly applied in computer vision tasks such as object detection, image segmentation, and autonomous driving systems.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
