

Parking Space Detection Model Using PyTorch and Super Gradients


Introduction
Did you know that the average American commuter spends 17 hours per year looking for parking, costing $345 per driver in wasted time, fuel, and emissions.
This parking problem not only causes frustration but also contributes to traffic congestion and pollution.
In response, cities and businesses are increasingly using AI-driven parking space detection systems, which can streamline parking management, improve city traffic flow, and reduce emissions.
Parking space detection systems play a pivotal role in modern urban environments, aiding in effective traffic management and enhancing the efficiency of smart city initiatives.
In this detailed tutorial, we'll learn how to create a robust parking space detection system using PyTorch, a powerful deep learning library, and leveraging the Super Gradients library for streamlined model training and evaluation.
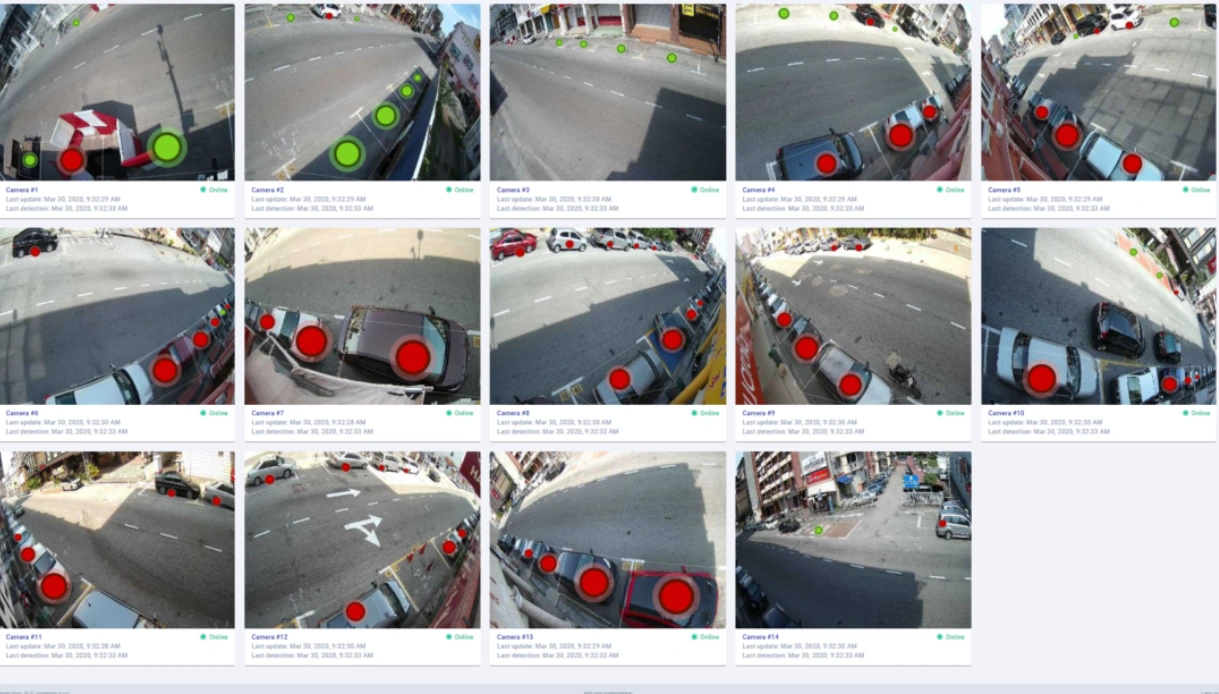
From dataset preparation to training and model evaluation, we’ll cover each step in detail to help you build a high-performing detection system.
Table of Contents
- Introduction
- About Dataset
- Hands-on Tutorial
- Advantages of Parking Space Detection
- Frequently Asked Questions
About Dataset
The "Parking Space Detection and Classification" dataset used in this model is a comprehensive collection of images capturing parking lots, accompanied by annotated bounding box masks highlighting individual parking spaces.
This dataset is tailored to facilitate object detection, localization, and classification tasks specifically related to parking space management.
Dataset Description
Image Annotations: Each image within the dataset comes with corresponding annotations in the form of bounding box masks.
These masks precisely outline the boundaries of parking spaces within the images, enabling accurate identification and localization of individual parking spots.
Parking Space Labels: Every parking space is labeled based on its occupancy status.
Free Parking Space: Designates unoccupied parking spots, represented by blue bounding box masks.
Occupied Parking Space: Indicates occupied parking spots, marked with red bounding box masks.
Partially Free Parking Space: Denotes parking spaces partially occupied, outlined by yellow bounding box masks.

Dataset Structure
The dataset is organized into the following structure:
Images: Contains original pictures of parking lots.
boxes: Includes bounding box annotations corresponding to the original images.
annotations.xml: Provides detailed coordinates of the bounding boxes and labels associated with parking spaces in the original photos.
Hands-on Tutorial
Prerequisites
Before diving into this tutorial, it's recommended to have:
(i) Basic proficiency in Python programming
(ii) Familiarity with deep learning concepts and the PyTorch framework
Tutorial
1. Setting Up the Environment and Dependencies
Install necessary libraries and import essential modules required for the project.
Library Installation: The code uses pip commands to install required libraries, including Super Gradients, Pillow (image processing library), TorchVision, and Torch.
Module Imports: Key modules such as os, random, torch, requests, and PIL (from the Pillow library) are imported. Additionally, modules from the Super Gradients library for training, data loading, models, losses, and metrics are imported.
%%capture
!pip install super-gradients
!pip install --upgrade pillow
!pip install --upgrade torchvision
!pip install torch!pip install torch torchvision
import os
import random
import torch
import requests
from PIL import Image
from super_gradients.training import Trainer, dataloaders, models
from super_gradients.training.losses import PPYoloELoss
from super_gradients.training.metrics import DetectionMetrics_050
from super_gradients.training.dataloaders.dataloaders import (
coco_detection_yolo_format_train,
coco_detection_yolo_format_val
)
from super_gradients.training.models.detection_models.pp_yolo_e import (
PPYoloEPostPredictionCallback
)2. Configuration Settings
Define the configuration settings necessary for the project, including paths to dataset directories, model settings, dataset classes, and dataloader parameters.
Here, we set up paths for the dataset directories, establish classes for the parking space dataset, and configure various parameters related to the dataset, model, and training process.
class config:
#trainer params
CHECKPOINT_DIR = 'checkpoints' #specify the path you want to save checkpoints to
EXPERIMENT_NAME = 'race_number' #specify the experiment name
#dataset params
DATA_DIR = '/kaggle/input/parking-space-get-annotation-info-from-xml/datasets'
#parent directory to where data lives
TRAIN_IMAGES_DIR = 'train/images' #child dir of DATA_DIR where train images are
TRAIN_LABELS_DIR = 'train/labels' #child dir of DATA_DIR where train labels are
VAL_IMAGES_DIR = 'valid/images' #child dir of DATA_DIR where validation images are
VAL_LABELS_DIR = 'valid/labels' #child dir of DATA_DIR where validation labels are
# if you have a test set
TEST_IMAGES_DIR = 'test/images' #child dir of DATA_DIR where test images are
TEST_LABELS_DIR = 'test/labels' #child dir of DATA_DIR where test labels are
CLASSES = ['free_parking_space','not_free_parking_space','partially_free_parking_space']
NUM_CLASSES = len(CLASSES)
#dataloader params - you can add whatever PyTorch dataloader params you have
#could be different across train, val, and test
DATALOADER_PARAMS={
'batch_size': 4,
'num_workers': 2
}
# model params
MODEL_NAME = 'yolo_nas_l' # choose from yolo_nas_s, yolo_nas_m, yolo_nas_l
PRETRAINED_WEIGHTS = 'coco' #only one option here: cocotrainer = Trainer(experiment_name=config.EXPERIMENT_NAME,
ckpt_root_dir=config.CHECKPOINT_DIR)3. Data Loading and Visualization
Dataset Loading: The code uses functions like coco_detection_yolo_format_train and coco_detection_yolo_format_val to load training, validation, and test datasets. These functions take dataset parameters (data directory, image directory, label directory, classes) and data loader parameters (batch size, number of workers) as inputs.
train_data = coco_detection_yolo_format_train(
dataset_params={
'data_dir': config.DATA_DIR,
'images_dir': config.TRAIN_IMAGES_DIR,
'labels_dir': config.TRAIN_LABELS_DIR,
'classes': config.CLASSES
},
dataloader_params=config.DATALOADER_PARAMS
)
val_data = coco_detection_yolo_format_val(
dataset_params={
'data_dir': config.DATA_DIR,
'images_dir': config.VAL_IMAGES_DIR,
'labels_dir': config.VAL_LABELS_DIR,
'classes': config.CLASSES
},
dataloader_params=config.DATALOADER_PARAMS
)
test_data = coco_detection_yolo_format_val(
dataset_params={
'data_dir': config.DATA_DIR,
'images_dir': config.TEST_IMAGES_DIR,
'labels_dir': config.TEST_LABELS_DIR,
'classes': config.CLASSES
},
dataloader_params=config.DATALOADER_PARAMS
)Dataset Visualization: After loading the training dataset (train_data), the plot() method is called to visualize a sample of the dataset, giving an overview of the dataset's structure and content.
train_data.dataset.plot()
4. Model Definition and Training Parameters
Define the architecture of the model and set up the parameters required for training.
Model Architecture: The code uses the models.get() function to obtain the model architecture based on the specified model name and the number of classes for parking space detection. Pretrained weights from the COCO dataset are used to initialize the model.
Training Parameters: The train_params dictionary contains various training-related parameters such as optimizer, learning rate schedule, loss function, number of epochs, mixed precision training, and evaluation metrics.
model = models.get(config.MODEL_NAME,
num_classes=config.NUM_CLASSES,
pretrained_weights=config.PRETRAINED_WEIGHTS
)
train_params = {
# ENABLING SILENT MODE
"average_best_models":True,
"warmup_mode": "linear_epoch_step",
"warmup_initial_lr": 1e-6,
"lr_warmup_epochs": 3,
"initial_lr": 5e-4,
"lr_mode": "cosine",
"cosine_final_lr_ratio": 0.1,
"optimizer": "AdamW",
"optimizer_params": {"weight_decay": 0.0001},
"zero_weight_decay_on_bias_and_bn": True,
"ema": True,
"ema_params": {"decay": 0.9, "decay_type": "threshold"},
# ONLY TRAINING FOR 10 EPOCHS FOR THIS EXAMPLE NOTEBOOK
"max_epochs": 30,
"mixed_precision": True, #mixed precision is not available for CPU
"loss": PPYoloELoss(
use_static_assigner=False,
# NOTE: num_classes needs to be defined here
num_classes=config.NUM_CLASSES,
reg_max=16
),
"valid_metrics_list": [
DetectionMetrics_050(
score_thres=0.1,
top_k_predictions=300,
# NOTE: num_classes needs to be defined here
num_cls=config.NUM_CLASSES,
normalize_targets=True,
post_prediction_callback=PPYoloEPostPredictionCallback(
score_threshold=0.01,
nms_top_k=1000,
max_predictions=300,
nms_threshold=0.7
)
)
],
"metric_to_watch": 'mAP@0.50'
} 5. Model Training and Evaluation
This part involves training the model and evaluating its performance.
- Model Training: The
trainer.train()method trains the model using the provided training data and validation data while utilizing the definedtrain_params. - Model Evaluation: The
trainer.test()method evaluates the trained model using the test data. Evaluation metrics, such asDetectionMetrics_050, are used to measure the model's performance in detecting parking spaces.
trainer.train(model=model,
training_params=train_params,
train_loader=train_data,
valid_loader=val_data)best_model = models.get(config.MODEL_NAME,
num_classes=config.NUM_CLASSES,
checkpoint_path=os.path.join(config.CHECKPOINT_DIR,
config.EXPERIMENT_NAME, 'average_model.pth'))trainer.test(model=best_model,
test_loader=test_data,
test_metrics_list=DetectionMetrics_050(score_thres=0.1,
top_k_predictions=300,
num_cls=config.NUM_CLASSES,
normalize_targets=True,
post_prediction_callback=PPYoloEPostPredictionCallback(
score_threshold=0.01,
nms_top_k=1000,
max_predictions=300,
nms_threshold=0.7)
))tpaths=[]
for dirname, _, filenames in os.walk('/kaggle/input/parking-space-get-annotation-
info-from-xml/datasets/test/images'):
for filename in filenames:
tpaths+=[(os.path.join(dirname, filename))]
print(len(tpaths))
6. Making Predictions
This section demonstrates making predictions using the trained model on test images.
Generating Predictions: Paths to test images are collected using os.walk() to iterate through the test image directory. Then, the trained model makes predictions on these images with a confidence threshold. Finally, the show() method displays the predictions.
best_model.predict(tpaths, conf=0.4).show()Results:




Advantages of Parking Space Detection
1. Efficient Parking Management: Quickly locate available parking spaces, reducing search time.
2. Traffic Congestion Reduction: Smoother traffic flow in parking lots and nearby areas.
3. Improved User Experience: Convenient parking spot finding, boosting satisfaction.
4. Space Utilization Optimization: Optimize parking layouts for better efficiency.
5. Environmental Benefits: Decrease fuel consumption and emissions.
6. Smart City Integration: Integral part of smart city traffic management.
7. Enhanced Security: Monitor parking areas for improved safety.
8. Data-Driven Insights: Valuable data for urban planning and decision-making.
9. Navigation Integration: Real-time parking availability in navigation apps for better route planning.
Frequently Asked Questions
1. Can deep learning solve parking space detection?
Yes, deep learning excels in parking space detection by leveraging advanced neural network architectures to analyze images, detect parking spaces, and classify their occupancy status.
Techniques like object detection using convolutional neural networks (CNNs) combined with annotated datasets enable accurate identification of parking spots, aiding in efficient parking management, autonomous navigation, and smart city initiatives.
Deep learning models process visual data, extract features, and precisely locate parking spaces, offering effective solutions for occupancy detection and parking space management.
2. How does a parking space detection system work?
A parking space detection system initially identifies parking spots using techniques like locating parking lines with edge detectors, such as those available in OpenCV.
By processing images, these systems analyze visual cues, such as distinct line patterns, to detect parking boundaries. Edge detection algorithms identify edges within the image, highlighting parking lines, and subsequently segmenting parking spaces.
Machine learning models or algorithms analyze these segmented areas to classify and label parking spots based on occupancy status, allowing for efficient parking management and navigation within parking lots.
3. What is PyTorch unsupervised learning for parking detection?
PyTorch employs unsupervised learning methods, like autoencoders, to extract features from unlabeled parking space data.
These techniques allow the system to autonomously identify patterns in parking spot images, enabling detection and classification without labeled datasets.
This approach enhances parking detection systems by learning representations from data without explicit annotations, improving adaptability and efficiency in recognizing parking spaces.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
