

Best RLHF Libraries in 2026
In 2025, top RLHF libraries include TRLX and RL4LMs. Both are open-source and vital for advancing language model training.


Imagine you're training a computer to understand and generate human-like language – that's what RLHF helps us do!
It's like teaching a computer to get better at talking, writing, and understanding language by giving it feedback.
RLHF is important because it helps us make those computer language models even smarter.
To make this process easier, there are special RLHF libraries.
These are like toolkits/frameworks for developers and researchers to fine-tune large language models, making them even more powerful and efficient.
In this blog, we'll talk about two of the best RLHF libraries – TRLX and RL4LMs.
These libraries make it easier for the computer to learn and understand language in an advanced way.
Let's dive into the exciting world of RLHF and explore how these libraries are making computers talk and understand like never before!
Table of Contents
Top RLHF Libraries
1. TRL and TRLX
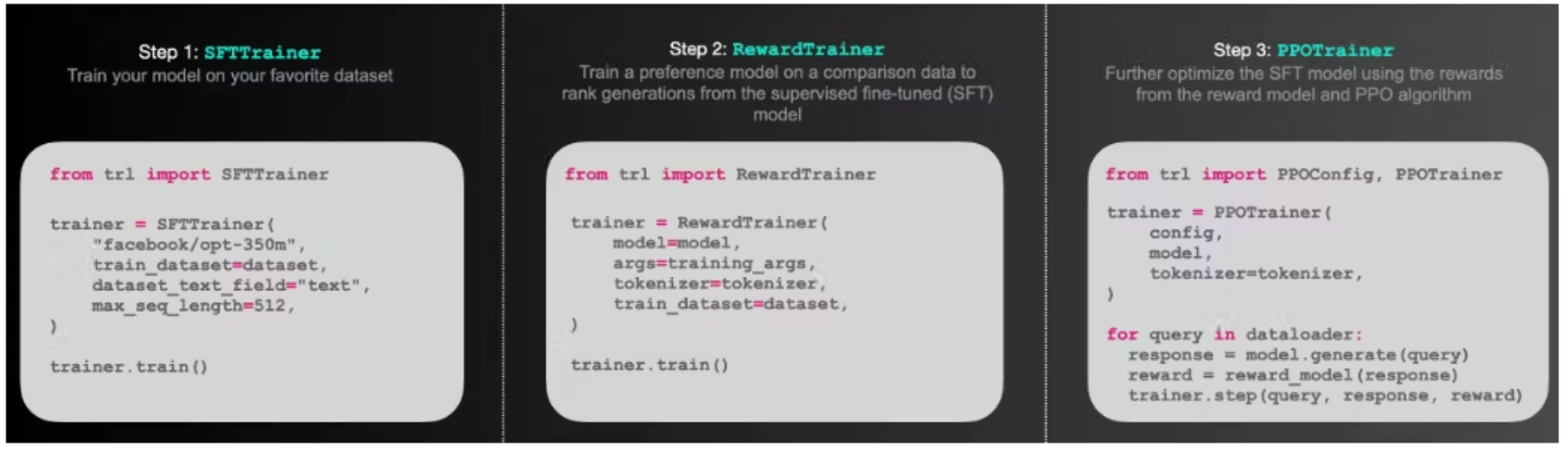
TRLX is a powerful tool for Reinforcement Learning from Human Feedback (RLHF) in Large Language Models.
TRLX, or Transformer Reinforcement Learning X is an advanced and user-friendly tool designed for fine-tuning large language models through reinforcement learning.
Unlike its predecessor TRL, TRLX brings in significant enhancements and is tailored for large-scale transformer-based language model development.
One of its key advantages is its support for models with up to 33 billion parameters, making it an ideal choice for teams working on extensive language model projects.
One notable feature of TRLX is its support for two reinforcement learning algorithms: Proximal Policy Optimization (PPO) and Implicit Language Q-Learning (ILQL).
This means it offers more flexibility in optimizing and refining models based on human feedback.
It allows developers to choose the algorithm that best suits their specific use case.
TRLX seamlessly integrates with Hugging Face models through Accelerate-backed trainers, offering a straightforward method to fine-tune causal and T5-based language models with up to 20 billion parameters.
For models exceeding this size, TRLX provides NVIDIA NeMo-backed trainers, leveraging efficient parallelism techniques for effective scaling.
It's worth noting that TRLX is an open-source tool, emphasizing accessibility for developers and researchers.
TRLX empowers teams to delve into large-scale language model development, offering advanced reinforcement learning capabilities to optimize model performance based on either a provided reward function or a reward-labeled dataset.
Whether you're working on a project with Hugging Face models or pushing the boundaries with models beyond 20 billion parameters, TRLX is a versatile and powerful tool for RLHF.
2. RL4LMs
RL4LMs is empowering Language Model Development with Reinforcement Learning from Human Feedback (RLHF).
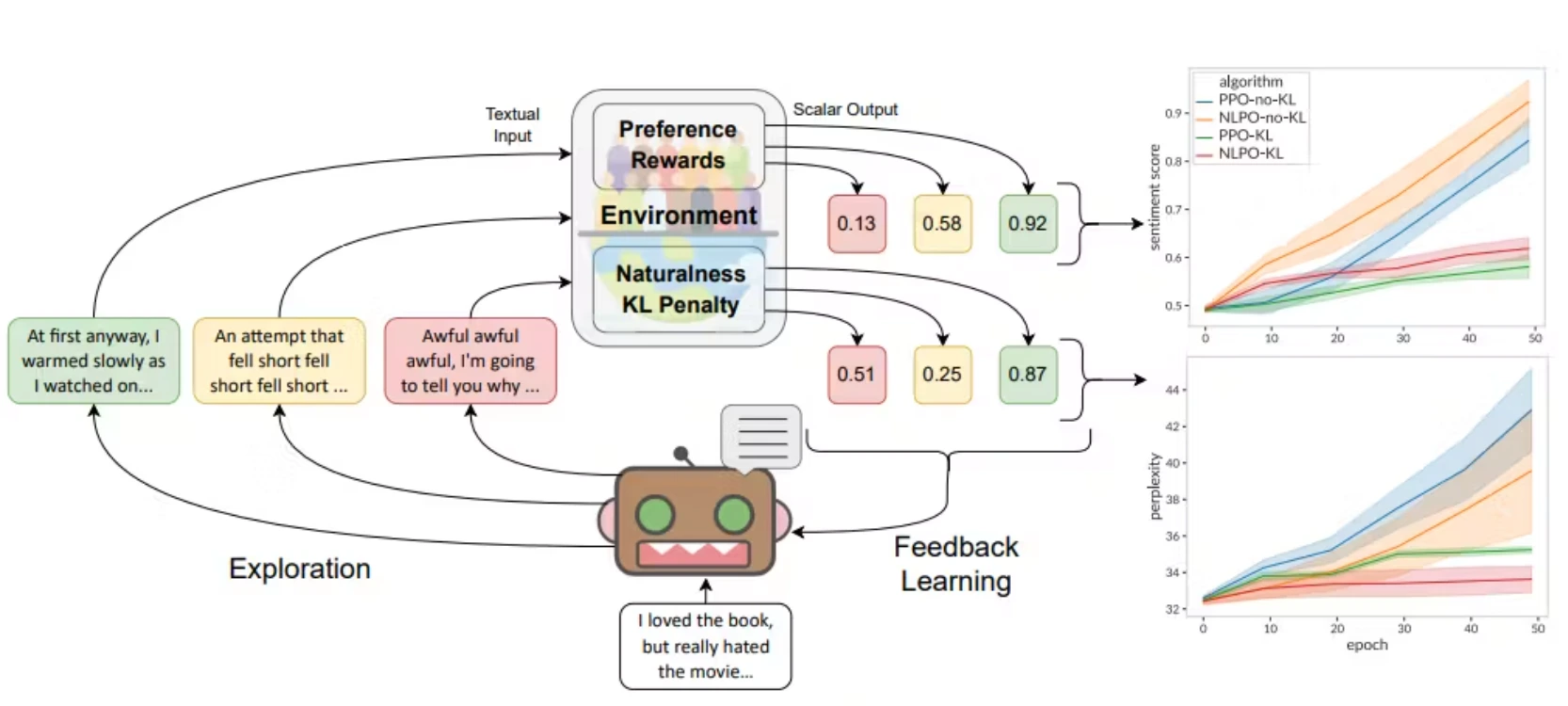
RL4LMs, or Reinforcement Learning for Language Models, emerged as a dynamic and open-source tool dedicated to RLHF.
It is tailored for training transformer-based language models.
RL4LMs offers various on-policy RL algorithms and actor-critic policies.
What sets it apart is its customizable building blocks, allowing developers to fine-tune language models with ease.
The library features on-policy RL algorithms, including popular ones like Proximal Policy Optimization (PPO), Advantage Actor-Critic (A2C), Trust-Region Policy Optimization (TRPO), and Natural Language Policy Optimization (NLPO).
This diverse set of algorithms provides flexibility in optimizing language models based on human feedback.
RL4LMs provide support for over 20 lexical, semantic, and task-specific metrics.
These metrics serve as valuable tools for crafting and fine-tuning reward functions which ensures that developers can optimize models for various aspects such as language understanding, coherence, and task-specific performance.
The versatility of RL4LMs shines through in their applicability to a range of tasks, including summarization, generative common-sense reasoning, and machine translation.
It becomes especially valuable for teams tackling complex language model projects, where defining a reward function and navigating a massive action space pose challenges.
Whether it's generating long-form stories or engaging in open-ended conversations, RL4LMs offers a valuable resource.
RL4LMs is open-source, emphasizing accessibility for developers and researchers.
RL4LMs stand out as a powerful tool for those venturing into language model development, providing a rich set of algorithms and metrics to enable effective RLHF and enhance language model capabilities.
Conclusion
Exploring the world of Reinforcement Learning from Human Feedback (RLHF) and its powerful libraries, TRLX and RL4LMs, has been an exciting journey.
These libraries act like guides, helping computers understand and talk like humans through advanced training techniques.
TRLX stands out with its user-friendly design, support for massive language models, and flexible reinforcement learning algorithms, making it an ideal choice for large-scale projects.
On the other hand, RL4LMs offers a dynamic and open-source approach, providing a rich set of customizable building blocks and diverse algorithms for fine-tuning language models.
Both libraries emphasize accessibility for developers and researchers, making them valuable resources for anyone venturing into the fascinating realm of language model development.
With TRLX and RL4LMs, computers are not just learning language – they're evolving to communicate and understand in ways we've never imagined!
Frequently Asked Questions
1. What language model does rlhf use?
Reinforcement Learning from Human Feedback (RLHF) utilizes transformer-based language models.
These language models, such as those used in TRLX and RL4LMs, are built on transformer architecture, a type of neural network that excels in processing sequential data.
Transformer-based models have proven highly effective in capturing complex language patterns, allowing RLHF libraries to fine-tune and optimize large language models through advanced reinforcement learning techniques.
The transformer architecture's versatility and efficiency make it a foundational choice for enhancing language understanding and generation in RLHF applications.
2. What is rl4lms?
RL4LMs, or Reinforcement Learning for Language Models, is a dynamic and open-source tool specifically tailored for Reinforcement Learning from Human Feedback (RLHF).
This library is designed to train transformer-based language models, offering a range of on-policy RL algorithms and actor-critic policies.
What sets RL4LMs apart is its customizable building blocks, providing developers with flexibility in fine-tuning language models.
It supports popular RL algorithms like Proximal Policy Optimization (PPO), Advantage Actor-Critic (A2C), Trust-Region Policy Optimization (TRPO), and Natural Language Policy Optimization (NLPO).
RL4LMs also offers support for over 20 lexical, semantic, and task-specific metrics, enabling the crafting and refinement of reward functions for optimizing language models based on human feedback.
This open-source tool proves valuable for diverse language model tasks, including summarization, generative common-sense reasoning, and machine translation, making it a powerful resource for enhancing language model capabilities through effective RLHF.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
