

6 Best Automatic Speech Recognition (ASR) Tools
Discover the best speech recognition software in 2025 to streamline workflows, boost accuracy, and automate transcription effortlessly.

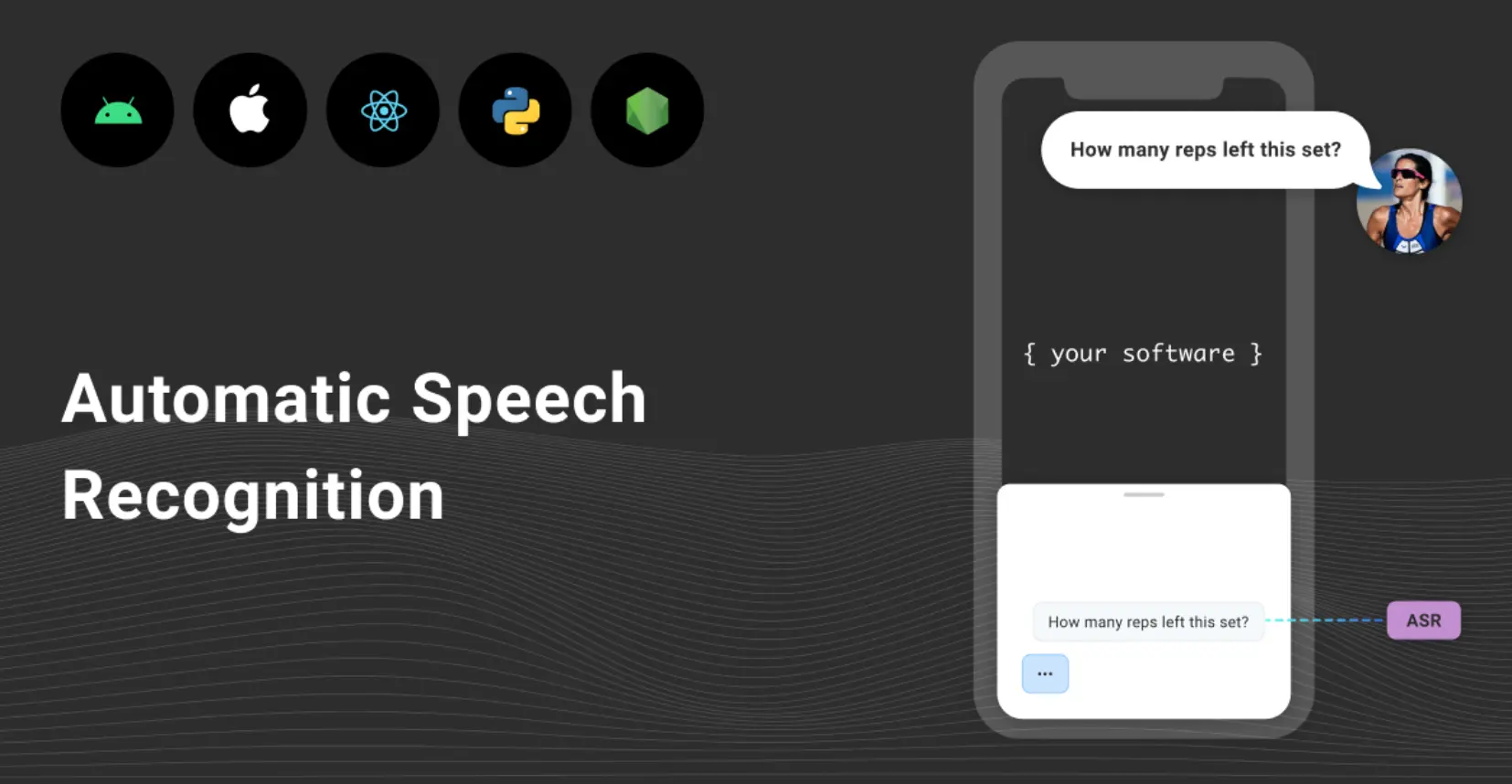
Imagine a world where transcribing hours of meetings, podcasts, or lectures no longer feels like a time-sucking chore.
It’s possible now, and in 2024, automatic speech recognition (ASR) tools have evolved to become more than just a convenience—they’ve become a game changer.
But here's the catch: not all speech recognition software is created equal. Some are still riddled with inaccuracies or require a level of technical know-how that can leave you feeling frustrated.
What if you could skip the struggle of manually transcribing audio and jump straight into productive tasks? What if the tool you used could transcribe speech with near-perfect accuracy, adapt to different accents, and handle noisy environments without missing a beat?
Enter the world of ASR tools.
In this post, we’re going to explore the best of 2024, from cutting-edge solutions. Each tool offers a unique feature set to match your specific needs, helping you move faster, smarter, and more efficiently than ever before. Ready to revolutionize your workflow?
Keep reading!
Table of Contents
- What is Speech Recognition?
- Benefits of Speech Recognition Tools
- Labellerr
- Google Cloud Speech-to-Text
- Deepgram
- Kaldi
- Simon
- Express Scribe
- Mozilla
- Conclusion
- Frequently Asked Questions
What is Speech Recognition?
Speech recognition technology is a groundbreaking innovation that empowers systems to comprehend spoken language input. It enables machines to recognize and interpret words and phrases, and subsequently convert them into machine-readable formats.
It entails the development of computer programs specifically engineered to decipher human speech input, analyze its linguistic components, and accurately transcribe it into written text.
Benefits of Speech Recognition Tools
1. Streamlined Business Processes
Speech recognition tools play a pivotal role in modernizing and optimizing business operations by automating various tasks and processes.
Companies can streamline data entry, documentation, and communication processes by seamlessly integrating speech recognition capabilities into their workflows.
For instance, during phone calls, these tools can instantly provide insights into ongoing conversations, facilitating prompt decision-making and enhancing overall operational efficiency.
2. Cost Efficiency
One of the most significant advantages of speech recognition tools lies in their cost-effectiveness.
Compared to manual transcription methods, which often entail significant time and labor costs, speech recognition software offers a more efficient and economical solution.
By automating the speech recognition and transcription process, these tools can perform tasks faster and more accurately than human counterparts, resulting in lower costs per minute of transcription.
Moreover, the scalability and efficiency of speech recognition technology translate into long-term cost savings for businesses across various industries.
3. Enhanced Accuracy and Speed
Speech recognition tools leverage advanced algorithms and machine learning techniques to transcribe spoken language into text with remarkable precision accurately.
These tools can effectively decipher diverse accents, dialects, and speech patterns by harnessing the power of artificial intelligence and natural language processing, ensuring high-quality transcription outputs.
Moreover, the real-time nature of speech recognition enables users to capture and transcribe spoken content rapidly, facilitating swift decision-making and response times in dynamic business environments.
4. Accessibility and Ease of Use
Accessibility is another key benefit of speech recognition tools, as they are readily available and user-friendly.
Many speech recognition software solutions come pre-installed on computers, smartphones, and other devices, making them easily accessible.
Furthermore, these tools typically offer intuitive interfaces and customizable settings, allowing users to tailor the software to their specific needs and preferences.
As a result, individuals across diverse industries and skill levels can leverage speech recognition technology to enhance their productivity and communication capabilities.
Speech recognition tools offer a multitude of benefits, ranging from improved operational efficiency and cost savings to enhanced accuracy and accessibility.
By harnessing the power of cutting-edge technology, businesses can leverage speech recognition solutions to streamline workflows, boost productivity, and stay ahead in today's digital world.
6 Best Automatic Speech Recognition (ASR) Tools in 2024
1. Labellerr
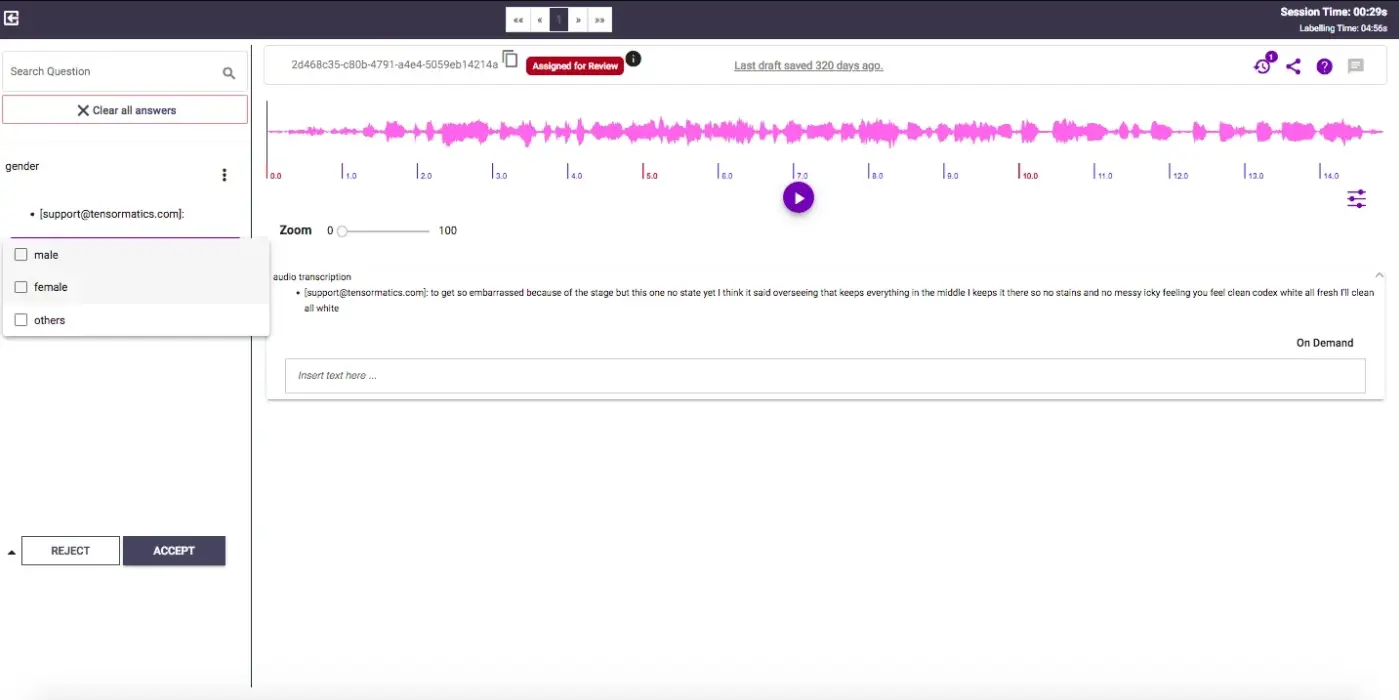
Labellerr offers an advanced data labeling platform that now includes Automatic Speech Recognition (ASR) capabilities.
With a focus on AI-assisted transcription, Labellerr streamlines the process of speech-to-text for multiple languages and accents. Its ability to integrate with existing machine learning pipelines makes it a solid choice for teams working on audio and speech-related tasks.
Top Features:
- AI-powered speech recognition for accuracy.
- Support for various languages and dialects.
- Seamless integration with ML workflows.
- Real-time transcription with customizable formats.
Pros:
- Scalable for enterprise-level projects.
- High accuracy with AI-enhanced features.
- Flexibility for a wide range of audio inputs.
Cons:
- Primarily tailored for speech-to-text tasks within specific industries.
- May require some setup for integration.
Pricing:
- Custom pricing based on the scale of the project.
G2 Review:
"Labellerr is incredibly user-friendly and efficient for data annotation. The intuitive UI and flexibility for collaborative projects are standout features. However, I experienced some latency and performance issues."
Turn your audio into text effortlessly with Labellerr’s Automatic Speech Recognition (ASR) tool. Try it free today and streamline your workflow!
2. Google Cloud Speech-to-Text
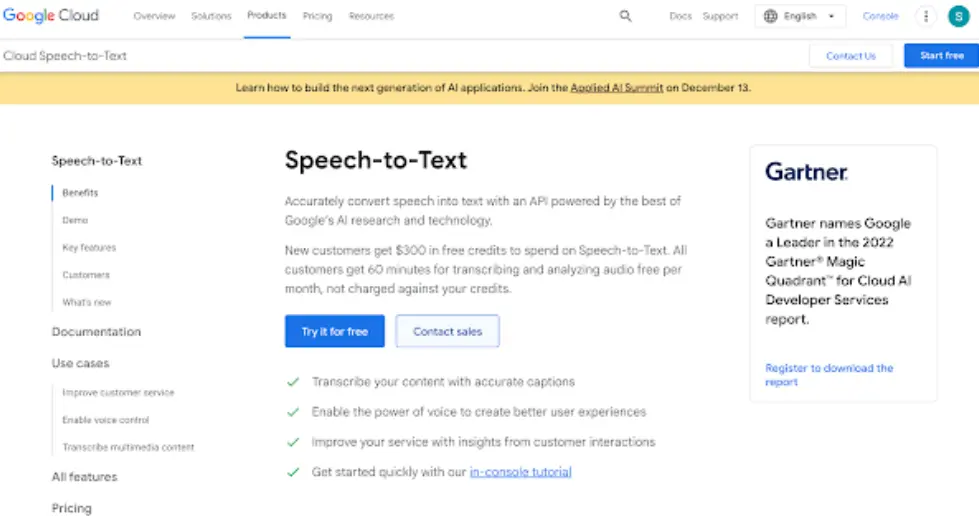
Google Cloud Speech-to-Text is one of the most widely used ASR tools. It provides fast, reliable, and accurate transcription services, supported by Google’s deep learning algorithms. This tool supports over 120 languages and is ideal for both real-time and batch transcription needs, making it a popular choice for businesses and developers.
Top Features:
- Supports over 120 languages and dialects.
- Real-time and batch processing capabilities.
- Speaker diarization to distinguish between multiple speakers.
- Integration with Google Cloud services for scalability.
Pros:
- Highly accurate, especially with noisy audio inputs.
- Real-time transcription with low latency.
- Easy integration with Google Cloud products.
Cons:
- Usage can become expensive for high volumes.
- Requires stable internet connectivity.
Pricing:
- Offers a free trial with 60 minutes of transcription and analysis and $300 free credits for new customers. Paid plans are based on monthly usage.
G2 Review:
"Google Cloud Speech-to-Text offers impressive transcription accuracy and supports multiple languages, which is fantastic for diverse applications. However, accent recognition can be tricky, and the pricing might be steep for some users."
3. Deepgram
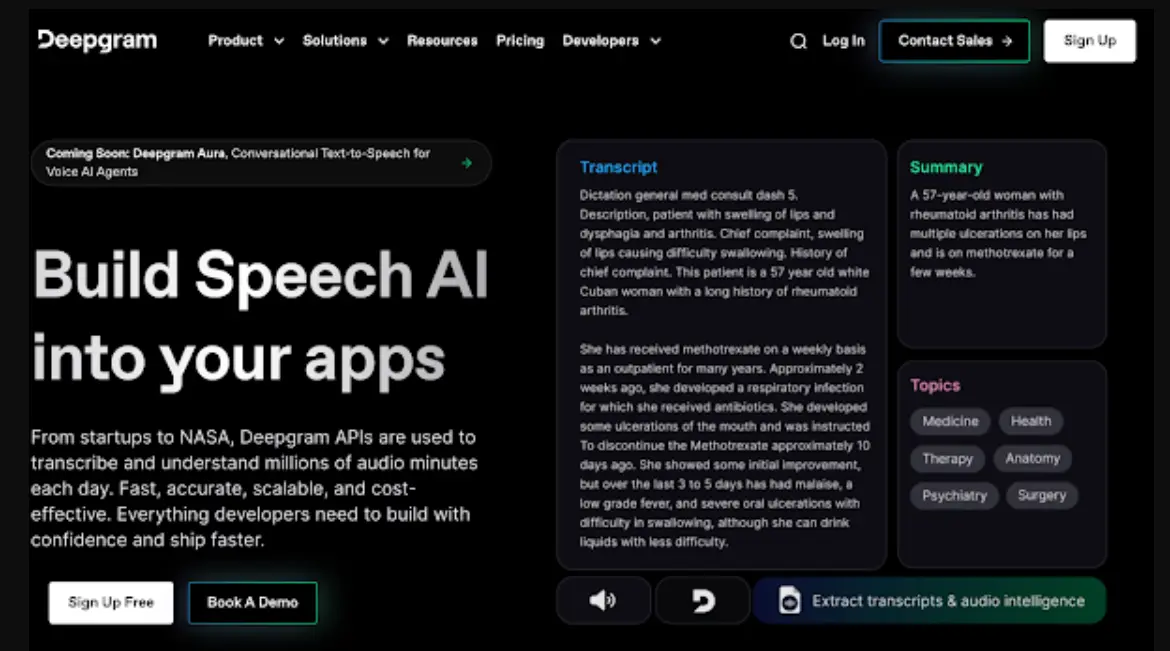
Deepgram offers an AI-powered ASR platform built for high-accuracy speech-to-text conversion. It stands out with its ability to adapt to different industries, from healthcare to customer service, providing customizable transcription solutions. Deepgram uses deep learning models that ensure both speed and precision in processing speech.
Top Features:
- Industry-specific speech models for tailored transcription.
- Real-time and batch transcription options.
- Advanced features like sentiment analysis and keyword extraction.
- Flexible API for easy integration.
Pros:
- High accuracy with specialized speech models.
- Customizable for specific industry needs.
- Excellent customer support and training resources.
Cons:
- More expensive compared to basic transcription tools.
- Limited free tier for testing.
Pricing:
- Offers a free Pay As You Go plan with a $200 credit.
- Growth Plan: Priced between $4,000 and $10,000 annually.
- Enterprise Plan: Pricing is available upon request. Interested users can contact the Deepgram team for detailed information.
G2 Review:
"Deepgram excels in speed and scalability, making it a reliable choice for transcription. The integration with existing systems is seamless. Yet, it is limited in language support and can be a bit costly."
4. Kaldi

Kaldi is an open-source ASR toolkit widely recognized for its flexibility and robust features. Popular among researchers and developers, Kaldi allows deep customization and can be adapted to various languages and dialects. It's ideal for teams with technical expertise looking to build their own ASR models.
Top Features:
- Open-source and highly customizable.
- Supports a variety of languages and speech recognition techniques.
- Extensive library for acoustic modeling and feature extraction.
- Large community and support for academic research.
Pros:
- Highly flexible and adaptable for custom models.
- Free and open-source, great for research and development.
- Excellent community support for troubleshooting.
Cons:
- Requires technical expertise to set up and use.
- No ready-to-use platform or user interface.
Pricing:
- Free to use (open-source).
G2 Review:
"Kaldi is an open-source powerhouse for speech recognition. It's highly customizable, making it ideal for research purposes. The downside is its steep learning curve and the need for technical expertise."
5. Simon
Simon is an open-source ASR tool focused on voice control applications. It's highly customizable and suitable for users who need to create speech recognition systems for specific commands or vocabulary. Simon allows users to develop their own voice-driven systems for various platforms, from desktop to mobile.
Top Features:
- Fully customizable for command-based speech recognition.
- Open-source and free to use.
- Support for multiple languages and dialects.
- Easy integration into various platforms (Linux, Windows).
Pros:
- Great for voice control and hands-free applications.
- Completely customizable to specific needs.
- Open-source with no costs involved.
Cons:
- Not ideal for full transcription tasks or continuous speech.
- Requires technical expertise for setup and customization.
Pricing:
- Free (open-source).
G2 Review:
"Simon is a robust open-source tool supporting multiple languages, which is great for speech recognition research. However, it requires technical knowledge and comes with limited documentation."
6. Express Scribe
Express Scribe is a transcription software primarily aimed at professionals who require manual transcription assistance. While it’s not as automated as other ASR tools, it provides features that support semi-automated transcription with speed and accuracy. Ideal for transcribing interviews, podcasts, or lectures, Express Scribe supports a wide range of audio formats.
Top Features:
- Supports foot pedal controls for transcriptionists.
- Integration with multiple audio formats.
- Automatic timestamping and speed adjustment features.
- Built-in text editor for transcriptions.
Pros:
- Excellent for manual transcription with automated support.
- User-friendly interface for professional transcriptionists.
- Customizable for various transcription workflows.
Cons:
- Does not fully automate transcription, requiring human input.
- More suited for manual transcriptionists rather than automated needs.
Pricing:
- Free version is available with basic features.
- Paid versions with advanced functionality.
G2 Review:
"Express Scribe is straightforward and supports various audio formats, making it useful for transcriptionists. It lacks advanced features and has occasional bugs, but it's still a solid tool."
7. Mozilla DeepSpeech
Mozilla DeepSpeech is an open-source ASR engine developed by Mozilla. It's based on deep learning algorithms and designed to provide high-quality speech recognition for multiple languages. DeepSpeech is popular among developers who want to integrate speech recognition into their applications with a focus on privacy and transparency.
Top Features:
- Open-source and community-driven.
- Supports multiple languages with pre-trained models.
- Can be deployed locally for offline transcription.
- High accuracy due to deep learning techniques.
Pros:
- Open-source and free to use.
- It can be run locally for enhanced privacy.
- Strong community support for development and troubleshooting.
Cons:
- Requires some setup and technical knowledge.
- Accuracy may vary based on the quality of the training data.
Pricing:
- Free (open-source).
G2 Review:
"Mozilla's open-source nature and support for web technologies make it a favorite among developers. It's powerful but can be complex for beginners and requires technical know-how."
Conclusion
Speech recognition technology has revolutionized the way we interact with machines, enabling them to understand and interpret human speech accurately.
The various speech recognition tools discussed offer a wide range of benefits, including streamlined business processes, cost efficiency, enhanced accuracy and speed, and accessibility.
Whether transcribing audio recordings, automating tasks, or facilitating communication, these tools empower users to harness the power of speech for improved productivity and efficiency in various fields.
As technology continues to evolve, speech recognition tools will play an increasingly vital role in shaping the future of human-machine interaction.
Read our other listicles:
1. 6 Best Data Curation Tools for Computer Vision in 2024
2. 6 Best Image Recognition Tools in 2024
Frequently Asked Questions
1. What is automatic speech recognition (ASR)?
Automatic Speech Recognition (ASR) is a technology that enables computers to understand and transcribe spoken language into text or commands without human intervention.
It allows users to communicate with devices using their voice, facilitating hands-free interaction and enabling applications such as virtual assistants, voice-controlled devices, and speech-to-text transcription services.
2. How does speech recognition software work?
Speech recognition software operates through intricate processes to transform spoken language into text or commands that computers can comprehend.
Initially, the software receives audio input via a microphone or recording device.
This input undergoes preprocessing, which involves tasks such as noise reduction and volume normalization to enhance clarity.
Subsequently, the software extracts various features from the audio, including frequency and duration, which are then mapped to phonemes through acoustic modeling.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
