

BERT Explained: State-of-the-art Language Model For NLP
BERT, a transformer-based language model by Google AI, enhances NLP tasks like sentiment analysis and question answering through bidirectional context analysis. Fine-tuning BERT on smaller datasets yields cutting-edge results across industries.


Did you know that over 80% of all digital data is unstructured text, from emails to social media conversations?
Making sense of this vast amount of information is no easy feat, but that's where Google comes in.
As a pioneer in artificial intelligence and search technology, Google has once again pushed the boundaries with BERT (Bidirectional Encoder Representations from Transformers).
It’s a revolutionary model that’s changing the face of Natural Language Processing (NLP).
Built by Google’s AI research team, BERT has raised the bar for how machines understand and process human language, delivering state-of-the-art performance across a wide range of NLP tasks.
In this blog, we’ll dive into what makes BERT so powerful, how it’s reshaping NLP, and why it’s become a cornerstone of AI innovation.
Ready to explore the world of BERT?
Let’s get started!
What is BERT?
Developed in 2018, BERT is a cutting-edge machine learning framework for natural language processing (NLP).
It is based on transformer architecture and was created by researchers at Google AI Language. BERT uses the surrounding text to provide context and help computers understand the meaning of ambiguous words in the text.
It has produced cutting-edge outcomes in various NLP tasks, such as sentiment analysis and question-answering.
To improve its performance on specific NLP tasks, BERT can be fine-tuned with smaller datasets after being pre-trained on massive text corpora like Wikipedia.
BERT is a very sophisticated and complex language model that aids in automating language comprehension.
How does BERT stand out from other models?
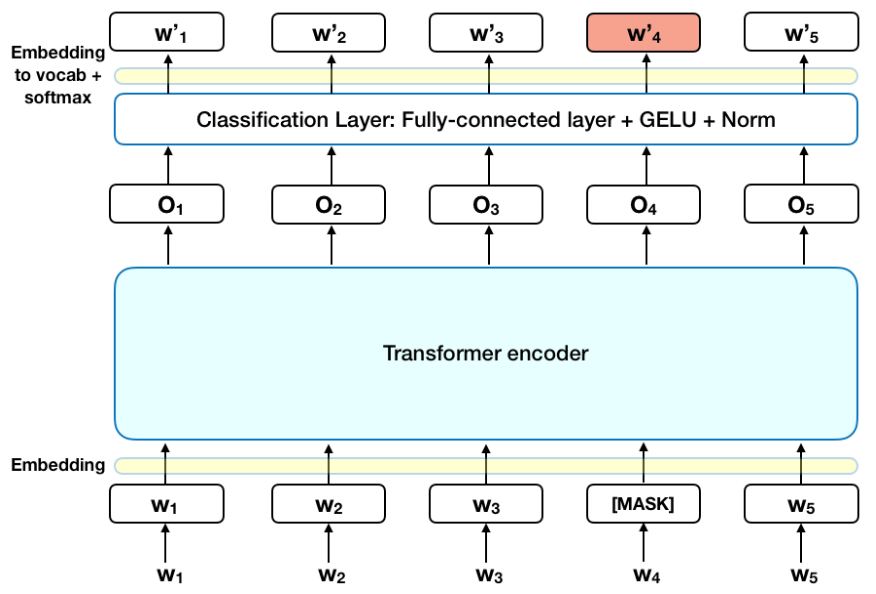
A state-of-the-art NLP model called BERT has outperformed earlier models in a variety of NLP tasks, including sentiment analysis, language inference, and question-answering.
Since BERT is profoundly bidirectional and unsupervised, it considers the context from both the left and right sides of each word, setting it apart from other NLP models.
In order to improve its performance on specific NLP tasks, BERT can be fine-tuned with smaller datasets after being pre-trained on huge text corpora like Wikipedia.
BERT's design makes it conceptually straightforward yet empirically effective since it enables the model to take into account the context from both the left and right sides of each word.
On eleven natural language processing tasks, BERT has produced new state-of-the-art results, surpassing human performance by 2.0%.
Examples include raising the GLUE benchmark to 80.4% (7.6% absolute improvement), MultiNLI accuracy to 86.7 (5.6% absolute improvement), and the SQuAD v1.1 question answering Test F1 to 93.2 (1.5% absolute improvement).
BERT continues to be a very successful and commonly used NLP model, despite the fact that other models, like GPT-3, have also demonstrated remarkable performance on a variety of NLP tasks.
Finding it an interesting read, then explore DINO: Unleashing the Potential of Self-Supervised Learning!
How does BERT's architecture differ from other NLP models?
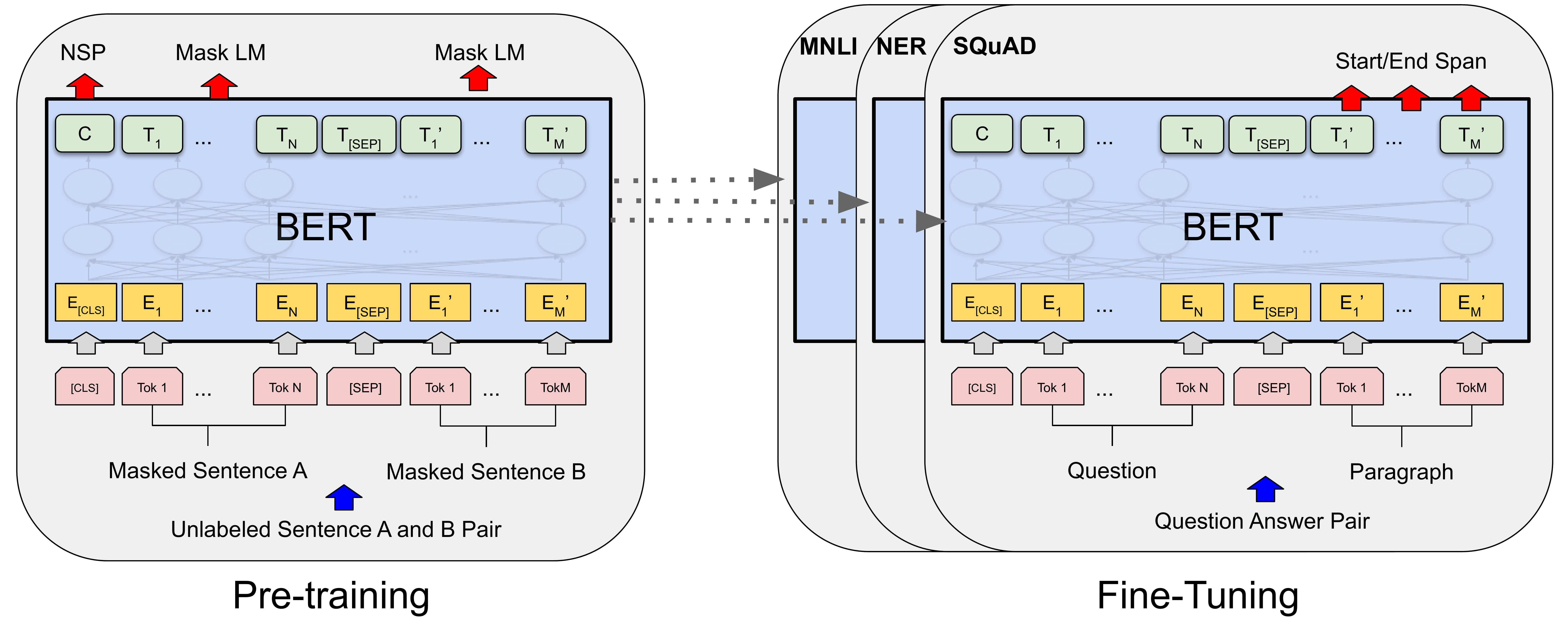
BERT’s architecture stands out from traditional NLP models, thanks to its foundation on the transformer architecture, which revolutionized how language is processed.
1. Contextual Understanding:
BERT is bidirectional, meaning it looks at both the left and right sides of each word in a sentence to understand its context.
In contrast, earlier models like Word2Vec and GloVe are context-free, meaning they produce a single, fixed representation for each word, no matter where it appears.
These older models lack the ability to account for the nuanced meaning of a word that changes based on its surrounding words.
Example: Take the word “bank.” Word2Vec or GloVe would give the same representation whether you're referring to a "river bank" or a "financial bank."
BERT, on the other hand, uses the full sentence to differentiate between meanings, understanding that "bank" by a river means something completely different from one where you deposit money.
2. Transformers vs. RNNs/Seq2Seq:
Traditional models often relied on Recurrent Neural Networks (RNNs) or sequence-to-sequence (Seq2Seq) architectures, which process data in one direction—either left-to-right or right-to-left.
These architectures struggle with long-term dependencies in a sentence and can lose important information when working with complex language.
BERT, built on the transformer model, doesn’t have this problem. Thanks to self-attention mechanisms, BERT can focus on the important parts of a sentence, regardless of its length, and effectively process long-range dependencies.
This allows BERT to better understand relationships between words, no matter how far apart they are in a sentence.
3. Task Flexibility:
Unlike older models that required task-specific architectures, BERT offers flexibility. You can fine-tune it for various NLP tasks, such as question answering, language inference, or sentiment analysis, by adding just a simple output layer.
This makes BERT incredibly versatile and adaptable, compared to models that require extensive architecture modifications for each new task.
In short, BERT’s architecture combines the power of transformers and bidirectional context, making it far superior to older, one-directional or context-free models when it comes to understanding the subtleties and complexities of human language.
What are Some Other State-of-the-art language models for NLP?
There are several state-of-the-art language models for NLP, and some of the most popular ones are:
ELMo
Embeddings from Language Models is a bidirectional LSTM-based deep contextualized word representation model that captures the context of words in a phrase.
Numerous NLP tasks, such as sentiment analysis, named entity identification and question answering, have been found to perform better when using ELMo.
GPT
A generic Pre-trained Transformer is a language model that has been pre-trained on a sizable corpus of text and employs a transformer-based design.
On a variety of language modeling tasks, such as text completion, summarization, and question answering, GPT has been demonstrated to produce cutting-edge results.
XLNet
eXtreme Multi-task Learning via Adversarial Training of a Language Model has a transformer-based architecture and has been pre-trained on a sizable corpus of text.
On a variety of NLP tasks, including text categorization, question answering, and natural language inference, XLNet has been demonstrated to produce state-of-the-art results.
These models are tailored for certain NLP tasks after being pre-trained with a vast quantity of data. They accomplish cutting-edge outcomes by utilizing sophisticated approaches including attention, dropout, and multi-task learning.
The most recent advances in NLP language models are driven by both the enormous increases in processing power as well as the development of clever techniques for lightening models while keeping excellent performance.
Applications of BERT
Because it works in both directions, BERT is a real powerhouse in Natural Language Processing (NLP). It does especially well at tasks that require understanding text in a deep contextual way. Its ability to look at both the left and right context of words has made it very good at a lot of different tasks.
Here are some key areas where BERT is making an impact:
- Named Entity Recognition (NER): BERT is very good at finding specific things in a text, like names, places, or organizations. This can be useful in fields like finance, where pulling entities out of documents can speed up tasks like finding fraud or analyzing contracts.
- Sentiment Analysis: BERT helps businesses better understand customer opinions by accurately analyzing sentiment in product reviews, social media posts, and customer feedback. This is especially valuable in e-commerce, where brands can quickly gauge public sentiment around their products.
- Question-Answering (QA): BERT has raised the bar for QA systems like Google's search engine by being able to understand user queries and give correct answers from large amounts of text. In healthcare, systems that are driven by BERT help doctors by answering questions based on clinical data or medical literature.
- Reading Comprehension: In the field of academic and education technology, BERT is great at reading comprehension tasks because it can fully understand passages of text and answer questions about them. This makes it useful for personalized learning platforms.
- Next-Sentence Prediction: BERT checks to see if two sentences make sense together. This helps chatbots, autocorrect, and writing assistants who need to keep the flow of a conversation going.
- Biomedical Entity Recognition: BERT has been improved to recognize medical terms. This makes it easier to get biomedical information from research papers, electronic health records, and other places. This has the potential to completely change biomedical research and healthcare.
BERT in Industry
BERT isn’t just confined to academia. It’s being applied in real-world industries to automate workflows, improve customer service, and enhance decision-making:
- Healthcare: BERT is used to look at medical records, help doctors make diagnoses, and process a lot of medical literature so that people can make better decisions.
- Banking & Finance: By processing legal and financial documents, BERT makes it easier to manage risk, find fraud, and follow the rules.
- E-commerce: BERT helps retailers improve the customer experience by determining what users want and recommending products that match those needs.
Multilingual Capabilities
As it can handle 103 languages, BERT is an essential tool for NLP applications that need to work with multiple languages. This lets companies around the world offer better customer service and automation tools in more than one language without having to make separate models for each one.
State-of-the-Art Performance
By achieving state-of-the-art scores on NLP benchmarks like the GLUE benchmark, MultiNLI accuracy, and the SQuAD v1.1 question-answering test, BERT has consistently performed better than previous models. These results show that BERT can understand difficult language tasks and make accurate predictions, which is beyond what NLP can do.
These are just some applications that explore how artificial intelligence is transforming businesses!
Conclusion
BERT's sophisticated language processing skills have significantly changed the NLP industry.
Its capacity for comprehending linguistic complexity and context has raised the bar for language models.
BERT is well-positioned to continue advancing the field of NLP and paving the path for more complex language models in the future because of its wide acceptance in industry and academics.
For more such interesting content, keep exploring Labellerr!
FAQs
- What is BERT?
BERT is a Bidirectional Encoder Representation from Transformers. Researchers at Google AI Language have created a cutting-edge language model for natural language processing (NLP).
2. How does BERT work?
BERT is a transformer-based model for language modeling that employs a bidirectional training strategy.
It is first fine-tuned for certain NLP tasks after being pre-trained on a sizable corpus of text. BERT achieves cutting-edge outcomes by utilizing sophisticated approaches including attention, dropout, and multi-task learning.
3. What NLP activities can be performed using BERT?
In a wide range of NLP tasks, such as Question Answering and Natural Language Inference, among others, BERT has demonstrated cutting-edge findings.
BERT may also be applied to text categorization, named entity identification, and sentiment analysis.
4. Does BERT provide accurate results?
On several NLP tasks, BERT has produced state-of-the-art results, and because it is updated constantly, its accuracy is exceptional. By adjusting the model for certain NLP tasks, the model's accuracy may be raised still more.
5. Is BERT available in a variety of languages?
Yes, the BERT model can be used for projects that are not English-based because it is accessible and pre-trained in more than 100 languages.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
