

How To Manage Data Annotation With Automated QC While Scaling Up


Data labeling is a necessary evil that every ML team has to face while training vision/NLP/LLM models. It is an iterative process so setting up the right process is very crucial for the success of model development or accuracy enhancement.
Traditionally it was handled with a complete manual setup, making it a very operation-heavy process. That makes ML teams very uncomfortable. That's why organization like Meta, Tesla, and Walmart put a dedicated data operation team that manage the complete process of manual annotation and verification of it.
Verifying the quality of labeled data i.e. training data is also very crucial as it guarantee the data is of high quality before pushing them to the model training pipeline.
Why does quality matter?
Imagine you are training your body for an Olympiad, you need a lot of training and to keep your energy and other nutrition you need to eat a good balanced diet that includes calories your body needs with carbs, protein, and other vitamins your body needs.
You can not train yourself with junk food.
Same with ML models, you need to feed it with good balanced data.
And a robust QC process is super important for that.
How To Automate My QC Process
Previous to GPT and foundation AI models, the first key pain used to be
"How can I label the data automatically?"
Now with the capability of OpenAI GPT4, and LLama3 to label text data faster and similar models such as SAM (Segment Anything) have helped a lot to reduce image annotation time significantly.
Caution:- though just applying SAM doesn't work, you still need to have a workflow and user experience in such a way that SAM helps you reduce your annotation time rather than increasing the effort. I will write on this as soon as I have heard from a couple of folks from both sides view
Some comments are pro-SAM -
SAM is awesome, its just automated image segmentation labeling for me
while others feel it is just another demo
it only works in the demoes and not in actual business scenarios. The incremental benefits are net negative. etc etc..
One of our users who works at Stanford Institute of Human-centered AI termed her experience using SAM inside Labellerr as
"1 click is all you need"
Anyways coming back to the topic of reducing time by automating quality assurance on labeled image datasets.
Now you might have got these images labeled internally by your team or your might have set up an image annotation pipeline on various tools such as Scale AI, Labellerr, Labelbox, Roboflow, V7 Labs, and Dataloop.
Here we are now more concerned about the challenges that even after soft guarantees from image annotation vendors or platforms about image annotation or even a model assisted labeling plus human in the loop approach, its important to keep an eye on the labeled data before it enters the model training pipeline.
And let me tell you What AI teams in Silicon Valley say about this-
A principal ML engineer working on wound healing computer vision use cases said "I am spending my team doing QA instead I should be spending my team on iterating on the ML experiments"
Another AI team head(a company based out of Boston, USA) told us that quality check is a bottleneck and nightmare since the analytics they offer to their customers are dependent on the quality of labeled data and the labels are subjective so they need to have someone double check the labeled data from their side
A similar scenario for a team working on robotics for warehousing said - "We are fast growing startup however we are short in terms of engineer's time already. Our hardware, software, and ML engineers all are spending time reviewing the labels even after getting them annotated from the top platforms such as ScaleAI, Labelbox, etc."
They are the experts so they know what is best however they wonder if there is a method that can incorporate all such domain knowledge and bake it into some sort of automation since having only domain experts is not scalable, especially in the United States.
Here are some of the most common methods that can be implemented to automate the QC process.
- QA with generative AI models
- QA with active learning-based models
- QA with unsupervised learning
- QA with customer models
- QA with ground truth data:
- QA with public datasets models
- QA with correlation analysis matching
- QA with heuristics
- Inter annotator agreement
Let me talk about each of the above strategies-
QA With Generative AI Models
For the object detection model creating training data with humans in the loop is generally much faster compare to other annotation type.
However, reviewing those image could be a daunting task for ML team as it need lots of patience and attention to detail to verify the quality.
Let's take the below example where we identified construction workers annotated with bounding boxes.

For review, the AI team can integrate Generative AI in the workflow and give prompts to the generative AI which supports visual question answering or multimodal AI.
Prompts could be at the image level or at each detection level respectively below
"Help me count people or construction workers in this image. Are these less or more than the number of bounding boxes labeled"

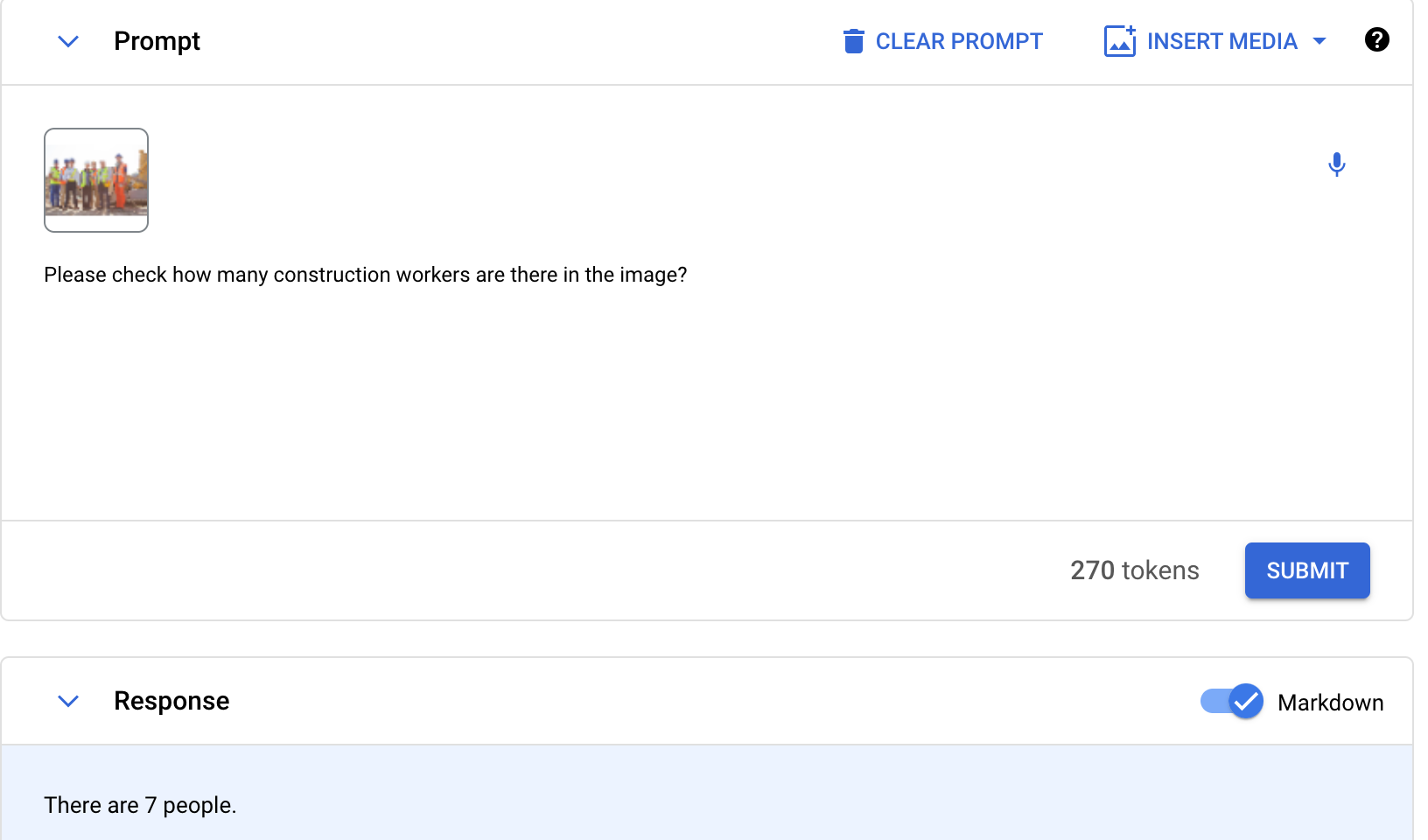
"Here are these multiple cropped images taken by cropping bounding box annotations. Please check whether the detection class is correct or not"

Once the Generative AI model provides its results, these can be checked at an image or each annotation level the accuracy.
The good news is - if you have this approach and you have a system of continuously adding the latest SOTA GenAI models into the workflow.
Either humans will be more accurate or SOTA models and in both ways it's a win.
This would also help you analyze what classes or scenarios where SOTA Generative AI models perform better and one can push that feedback into the automated data labeling layer as well to reduce human-in-the-loop effort basis these checks.
QA With Active Learning-Based Models -
Since the data is labeled already then we can use active learning-based models to bucketize scenarios of high and low confidence and then review them separately.
If there is a gap between the inference of humans and the model's high-confidence predictions, this could indicate issues - ideally, since the model has learned from this labeled data that means it needs to be looked into in detail.
For scenarios where the model is very low confidence that could also mean that those are edge cases and not well represented in the labeled dataset and so should be looked at since the guidelines might not be mature enough on those.
Apart from the model's limitations to learning these scenarios well, it could point to ambiguous images, errors, or noise in labeled data, less representation of those scenarios.
QA With Unsupervised Learning Approaches
Another great approach is to run clustering and other embedding-based approaches on images. By clustering one can group thousands of images based on similarity.
If there are 10 to 200 annotations per image this could mean evaluating from thousands to millions of annotations for thousands of images. Visual QC is not going to be feasible.
So clustering those many annotations and comparing them with human-labeled classes(in a way these are human annotators marked clusters) can be compared as below.
This could help focus reviewer focus on the most conflicting scenarios where each class contains a minority cluster.
For example, by filtering all the annotations for the class "Bus". There could be a scenario where cluster 1 might represent 70%, cluster 2 as 20%, and remaining cluster as 10% approx.
That means I need to first review the annotations of the minority cluster which could be erroneous in some way.
QA With Self Trained Models
If the AI team has already trained a model on the previous annotation, that could be integrated into the workflow to quickly identify gaps between model-generated predictions and human-generated labels.
Generally, these models are best representative of the real scenarios of the classes where it's performing best, this could be used to cross-check the scenarios.
It could be the case that there are additional heuristics applied to the model in the production environment to make it work as per the expected performance. those patterns and learnings at this layer can be used in QA.
QA with Ground Truth Data
Ground truth data is of high quality annotation that has been verified by domain expert.
It is also called golden data because is considered the top benchmark for data labeling for any particular use case.
The best part of it is that it can also help to generate more such ground truth in less effort.
Ground truth-based QA pipeline sprinkles some ground truth data with unlabeled data, where the manual annotation team has no idea which is unlabeled and which is ground truth.
One can easily compare the annotation of done by humans and compare with the already available annotation so see the quality.
It is considered one of the better way to ensure the quality of annotation.
One should target to put 10% of data as ground truth to effectively analyze the quality.
QA with public datasets models
There are tens of thousands of public datasets available that can be leveraged to augment a QA process.
But how?
AI teams can quickly take a public dataset from Kaggle or other sources similar to their use case and classes.
They can quickly get ground truth on it and train a base model that can be leveraged to compare the human annotation vs the model prediction.
They can compare the output on different parameters like high mismatch and low mismatch to get a quick sense of the problem area and based on which certain actions can be taken like-
- Training the annotation team to make a consensus to understand the nuances of classes.
- Find out the edge cases quickly in the dataset and update the annotation guidelines.
Few examples-
The KITTI dataset consists of gigabytes of street images that can be used to train a model for use cases like-
- Autonomous vehicles
- Robotics
- Smart city and more
-
Similarly, audio datasets are available that can help in QA for multiple use cases like question answering, conversations, and chatbot training.
Natural_questions, Ambig QA, and many others.
QA with correlation analysis matching -
In some cases, it has been found that certain classes appear with a pattern or occur when some other particular class also occur.
There is a high correlation in which certain objects/classes appear. For example-
If there is a question "Is there any human visible?"
and the next question is "How many humans are seen in the image?"
We can see if the answer to later is 1 or more then the answer to 1 can't be 'No'.
This kind of correlation also helps to do quick QC to assess the quality of human annotation.
QA With Heuristics And Rule-Based System
For this kind of QA setup, the team should have a good domain understanding.
It is a rule-based and heuristic approach to identifying mislabeling. It's like Orange the fruit can not tagged with the color purple.
For example OCR extraction of number plates, the team can connect to the database of car registration to quickly check if any license plate number is detected or found in the database or not.
If it is not found, the AI team can see those images first to identify the issue.
Another example would be if a pedestrian can be a person as well. So if you are detecting pedestrians then you can check it with a very accurate API or function to detect a person.
If some data doesn't detect "person" but your labeled data says it's a pedestrian, it can be looked at first.
Heuristics can also be like small annotated objects below some area that should not exist. For example in a waste management scenario where annotators should not mark too many small annotations.
QA With Inter Annotator Agreement
This is the most unique process to manage the quality of annotation where a high level of subjectivity is involved and we can not objectively define the scenario.
Generative AI model evaluation it is the most common technique that most team rely on.
It involve multiple annotator's point of view to label each image or data.
The system creates a consensus-based ranking to decide the final tag or answer.
For example- If one needs to evaluate the output of a model based on a prompt then different people might have different levels of likeness to the output.
And to handle it in the most objective way is to embrace subjectivity.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
