CLIP CLIP's Performance On Food Dataset: Here Are The Findings The CLIP (Contrastive Language–Image Pre-training) model represents a groundbreaking convergence of natural language understanding and computer vision, allowing it to excel in various tasks involving images and text. Its foundation is rooted in zero-shot transfer learning, which empowers the model to make accurate predictions on entirely new classes or
computer vision ViTMatte: A Leap Forward in Image Matting with Vision Transformers Table of Contents 1. Introduction 2. About VitMatte 3. Overall Architecture 4. Performance and Evaluation 5. Conclusion 6. Frequently Asked Questions Introduction Vision Transformers (ViTs) have recently demonstrated impressive capabilities in various computer vision tasks, owing to their robust modeling prowess and extensive pretraining. However, the challenge of image matting
computer vision Results Of CLIP's Zero-Shot Performance Over OCR Dataset CLIP demonstrates potential in zero-shot learning for OCR by classifying text sentiment images with 50% accuracy. Its ability to associate images with text enables it to adapt to unseen concepts, though precision (40%) reveals room for improvement through fine-tuning
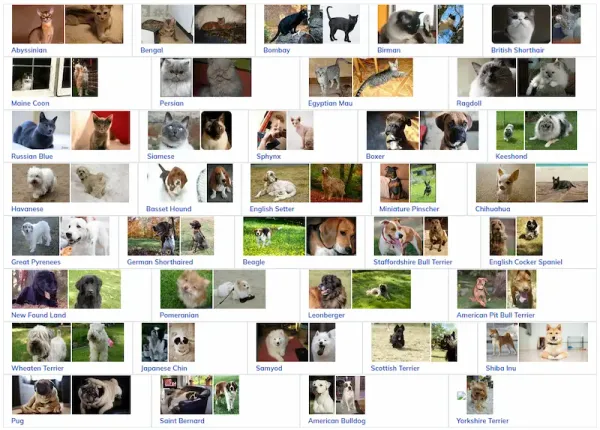
computer vision Zero-Shot Performance Of CLIP Over Animal Breed Dataset: Here're The Findings Table of Contents 1. Introduction 2. About Datasets 3. Hands-on With Code 4. Conclusion 5. Frequently Asked Questions (FAQ) Introduction The CLIP (Contrastive Language–Image Pre-training) model represents a groundbreaking convergence of natural language understanding and computer vision, allowing it to excel in various tasks involving images and text. Its
computer vision GEDepth: Bridging the Gap in Monocular Depth Estimation Table of Contents 1. Introduction 2. Ground Embedding 3. Model Evaluation 4. Conclusion 5. Frequently Asked Questions (FAQ) Introduction There is an inherent challenge in monocular depth estimation due to its ill-posed nature, where a single 2D image can originate from an infinite number of 3D scenes. Despite the substantial
computer vision ViNT Model Is Here, Let's See What It Can Do Table of Contents 1. Introduction 2. Model Architecture 3. Model Evaluation 4. ViNT Limitations 5. Frequently Asked Questions Introduction General-purpose pre-trained models, often referred to as "foundation models," have enabled the development of adaptable solutions for specific machine learning problems using smaller datasets compared to starting from scratch.
computer vision Transforming Computer Vision: The Rise of Vision Transformers And Its Impact Table of Contents 1. Introduction 2. ViT vs. Convolutional Neural Networks 3. Working of Vision Transformer 4. Applications of Vision Transformers 5. Benefits of Utilizing Vision Transformers 6. Drawbacks of Utilizing Vision Transformers 7. Conclusion 8. Frequently Asked Questions (FAQ) Introduction As introduced by Vaswani et al. in 2017, self-attention-based
computer vision Meta Launched Co-Tracker! This Is What We Have to Say About It. Table of Contents 1. Introduction 2. Co-Tracker Architecture 3. Essential Aspects of Co-Tracker's Functionality 4. Our Findings About Co-Tracker's Performance 5. Conclusion Introduction Last Month, Meta AI released a deep learning-based model for tracking objects in a video motion called Co-Tracker. Co-Tracker is a fast transformer-based
Machine Learning Different Methods To Employ Data Labelling In Machine Learning Tasks Often, data labeling goes hand in hand with data acquisition. When compiling information from the Web to create a knowledge base, each fact is considered accurate and is therefore implicitly labeled as true. In the context of data labeling literature, it's useful to separate it from data acquisition
fine-tuning of large language models Fine-Tuning Tutorial: Falcon-7b LLM To A General Purpose Chatbot Learn to fine-tune the Falcon-7b LLM into a versatile chatbot using techniques like PEFT and QLoRA. This guide walks through adapting large models for specific tasks, enhancing chatbot performance while optimizing resource use with tools like Hugging Face.
LLMs 6 LLMs Applications No One Is Talking About Large Language Models (LLMs) are reshaping fields from computational biology and code generation to creative arts, healthcare, robotics, and synthetic data generation, offering innovative solutions beyond common applications like chatbots.
LLMs Security Challenges in LLM Adoption for Enterprises And How To Solve Them In 2023, generative AI gained significant attention, but enterprises are facing challenges in identifying suitable use cases for this technology. Large Language Models (LLMs) have inherent limitations, such as generating irrelevant or off-topic content and being vulnerable to prompt injection, making them a source of concern for businesses. Figure: LLMs
security Securing AI System's Importance: Learning from Google's AI Red Team Red teaming is a critical cybersecurity practice that involves creating a team of ethical hackers, known as the "Red Team," to simulate real-world attacks and adversarial scenarios on an organization's systems, networks, or technology. In the context of AI systems, red teaming plays a decisive role
dino Enhanced Zero-shot Labeling through the Fusion of DINO and Grounded Pre-training Table of Contents 1. Introduction 2. Grounding DINO Architecture 3. Applications 4. Image Segmentation Using Grounded DINO and SAM 5. Image Editing Using Grounding DINO and Stable Diffusion 6. Conclusion 7. Frequently Asked Questions (FAQ) Introduction Visual intelligence requires the ability to understand and detect novel concepts. In the recent
labellerr Common Challenges and Solutions for Free Data Labeling Tools Table of Contents 1. LabelMe 2. VGG Image Annotator (VIA) 3. Make Sense 4. Imglab 5. Why Labellerr 6. Conclusion 7. Frequently Asked Questions Data labeling is of utmost importance in the field of machine learning and artificial intelligence as it provides labeled data, acting as ground truth, essential for
cvpr 23 CVPR 2023: Key Takeaways & Future Trends The atmosphere was charged with excitement at CVPR 2023 in Vancouver, the renowned conference for computer vision. Researchers and practitioners gathered to exchange ideas about the significant advancements in the field over the past year and discuss the future of computer vision and AI as a whole. The predominant subjects
labellerr Elevating ML: AI-Driven Data Annotation with LabelGPT Table of Contents 1. Introduction 2. Pre-requisite Concepts for Automated Data Labelling 3. About Foundation Models 4. Overview of Zero-Shot Learning and Its Role in Automated Data Labeling 5. Generative AI-Powered Prompt-Based Data Labeling 6. LabelGPT 7. How LabelGPT Works 8. Benefits of LabelGPT 9. Conclusion 10. Frequently Asked Questions
computer vision Computer Vision Data Drift - Why It's Important To Manage & How? As the circumstances in which a computer vision model operates change, the model needs to be updated to ensure its adaptability. For instance, consider a model used to identify objects in a retail store. As new products are introduced, store layouts are modified, and lighting conditions fluctuate, the model'
edge ai Edge AI: Deployment of AI/ML Models Via Compression of Machine Learning Models Table of Contents 1. Introduction 2. Challenges in the Deployment of ML Models over Edge Devices 3. Technology Behind Models Compression 4. Conclusion 5. Frequently Asked Questions (FAQ) Introduction Are you confident that maximum potential is being achieved in neural networks? It's possible that untapped opportunities are being
human activity recogonition Human Activity Recognition (HAR): Fundamentals, Models, Datasets Table of Contents 1. Introduction 2. What is Pose Estimation? 3. How Does AI-Based Human Activity Recognition Work? 4. Some Important Datasets for Human Activity Recognition 5. Real-Life Applications of Human Activity Recognition 6. Conclusion 7. Frequently Asked Questions (FAQ) Introduction Human activity recognition (HAR) refers to using computer and
deployment Insights And Best Practices For Building and Deploying Computer Vision Models Building and deploying computer vision (CV) models require a deep understanding of both the theoretical aspects of computer vision and the practical challenges of developing robust and efficient systems. Computer Vision Engineers play a critical role in this process, leveraging their expertise to design, train, and deploy CV models that
computer vision Foundation Models for Image Search: Enhancing Efficiency and Accuracy Foundation models like CLIP and GLIP are transforming the way businesses use AI for visual search. These advanced systems leverage multimodal capabilities to enhance image search model accuracy by linking text and visuals, making searches faster, more precise, and highly adaptable.
Machine Learning Advancing Performance in Automating Invoice Processing Large companies dealing with a high volume of invoices daily show great interest in automatic invoice processing systems. These systems are attractive not only because of their legal requirement to store invoices for years but also due to economic reasons. Figure: Bills and Invoices Cristani et al. compared manually processed
Large Language Models How To Enhance Performance and Task Generalization in LLMs From the previous blog, we studied that Pre-training forms the foundation of LLMs' abilities. LLMs acquire crucial language comprehension and generation skills through pre-training on extensive corpora. The size and quality of the pre-training corpus play a vital role in enabling LLMs to possess powerful capabilities. Moreover, the design
deep learning Efficient Tuning LLMS: Optimize Performance with Fewer Parameters Table of Contents 1. Introduction 2. Parameter-Efficient Fine-Tuning Methods 3. Adapter Tuning 4. Prefix Tuning 5. Prompt Tuning 6. Low-Rank Adaptation (LoRA) 7. Conclusion Introduction Tuning plays a crucial role in the development and effectiveness of Language Models (LLMs). LLMs are pre-trained on vast amounts of text data to acquire