

Improving ASR Models Using LLM-Powered Workflow


Introduction
Computers can now convert spoken words into text thanks to a technology called Automatic Speech Recognition (ASR). Applications using it include voice assistants, dictation systems, and automated customer service. ASR enables dictating documents, emails, and messages hands-free.
It also supports natural language information search on smartphones and smart speakers via voice search. It is the foundation of voice commands for music playback, reminders, and smart home device control that virtual assistants like Siri and Alexa understand and respond to.
According to 86% of US executives, AI will become a common tool for companies by 2021. By 2030, conversational AI is predicted to be worth $32.62 billion.
Conversational artificial intelligence has enormous promise to completely change how we use technology. This technology is set to simplify procedures, customize encounters, and increase accessibility in everything from healthcare to education and customer service.
In this article, we are going to discuss:
Table of Contents
- Evolution of ASR
- Integration of LLMs with ASR
- How are companies leading the way with LLM-Enhanced ASR?
- Current trends with ASR
- Challenges and Limitations of ASR
- The Future of ASR
- How to improve your ASR models with Labeller
- Conclusion
- FAQ
Evolution of ASR
Before we examine the trends and methods of today, let us take a closer look at the amazing history of ASR.
The early 1950s
The Audrey ASR system was the first to be developed and was introduced by Bell Labs in 1952. With its restricted recognition range of spoken digits (0–9), it was a revolutionary marvel of technology for its day. This groundbreaking technology cleared the path for the creation of the advanced ASR models that exist today.
The early 1960s
Ten years later, in 1961, IMB unveiled Shoebox, a system that could recognize numbers and simple arithmetic commands. These early systems could only accurately recognize single words due to a lack of complex algorithms and limited computing resources.
The graphical representation of the topics covered in this section is displayed in the picture below.
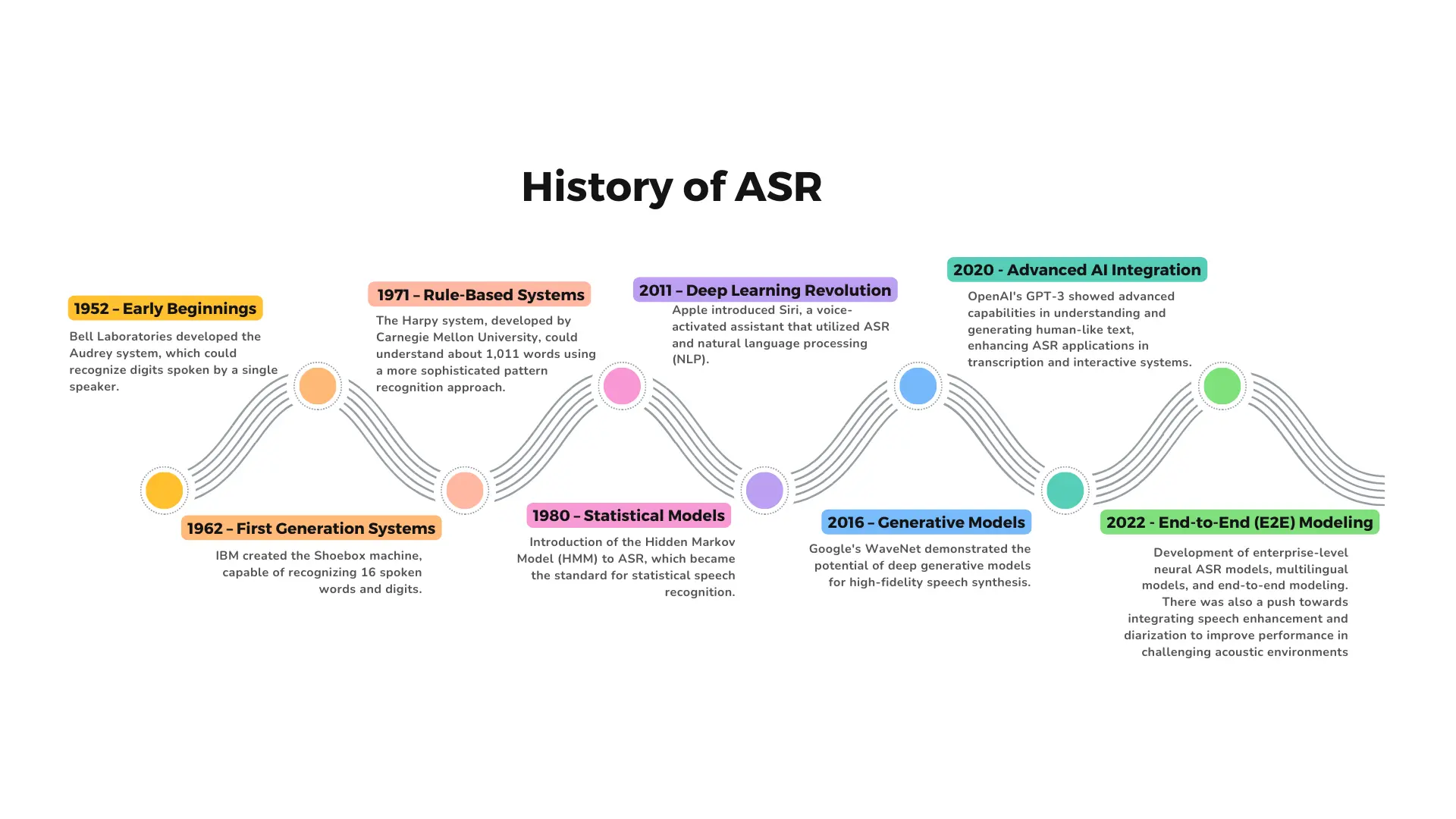
Mid 1970s-1980s
ASR models underwent substantial evolution over the years, taking advantage of developments in neural networks and machine learning. The development of Hidden Markov Models (HMMs) in the 1970s was one significant advancement that made speech recognition more precise.
These models examine the likelihood that speech sounds will appear one after the other statistically. Systems evolved to recognize short sentences and linked words.
1990s-2000s
Neural networks gained popularity in the field of ASR during the 1990s. Although initial implementations were promising, they were not yet strong enough to challenge HMMs. But with the introduction of deep learning architectures such as Recurrent Neural Networks (RNNs) in the 2000s, a new era came to light.
RNNs are a game-changer for ASR because they're excellent at learning complicated sequences. These models greatly increased accuracy, enabling far more precise handling of continuous speech by systems.
2010-2020s
Deep learning architectures saw more developments in the 2010s and beyond, with transformers and Long Short-Term Memory (LSTM) networks pushing limits on ASR performance. Even in difficult settings, these models' ability to handle complicated accents, background noise, and natural language variances results in extremely accurate detection.
Although these models are very good at identifying speech patterns, they are not perfect. Deep learning models analyze sounds and even forecast the next sound based on previously seen sequences, with a primary focus on the acoustic features of speech.
But language is not only a series of sounds in human speech. It entails comprehending the meaning of words, their context, and the speaker's overall intention. Sarcasm, tone of voice, and cultural references are a few examples of elements that add to meaning that are difficult to identify from sound analysis alone.
Large Language Models (LLMs) were established to address the issue mentioned above. Large volumes of text data are used to train LLMs, which helps them understand the nuances of human language.
They are able to understand syntax, grammar, and word relationships, constructing a thorough understanding of the meaning that a speaker is attempting to express. LLMs are capable of understanding the meaning underlying the speech, going beyond just identifying sounds.
Integration of LLMs with ASR
The integration of LLMs into Automatic Speech Recognition (ASR) systems is a recent area of study as these systems continue to evolve. LLMs have the potential to increase ASR accuracy because of their reputation for understanding and creating human language.
The goal of this integration is to take advantage of the advantages of both systems- the text-to-speech conversion skills of ASR and the contextual knowledge and sophisticated language structures of LLMs.
When combined, these technologies have the potential to produce more accurate and complex voice recognition, particularly in difficult scenarios like ambiguous pronunciations or background noise.
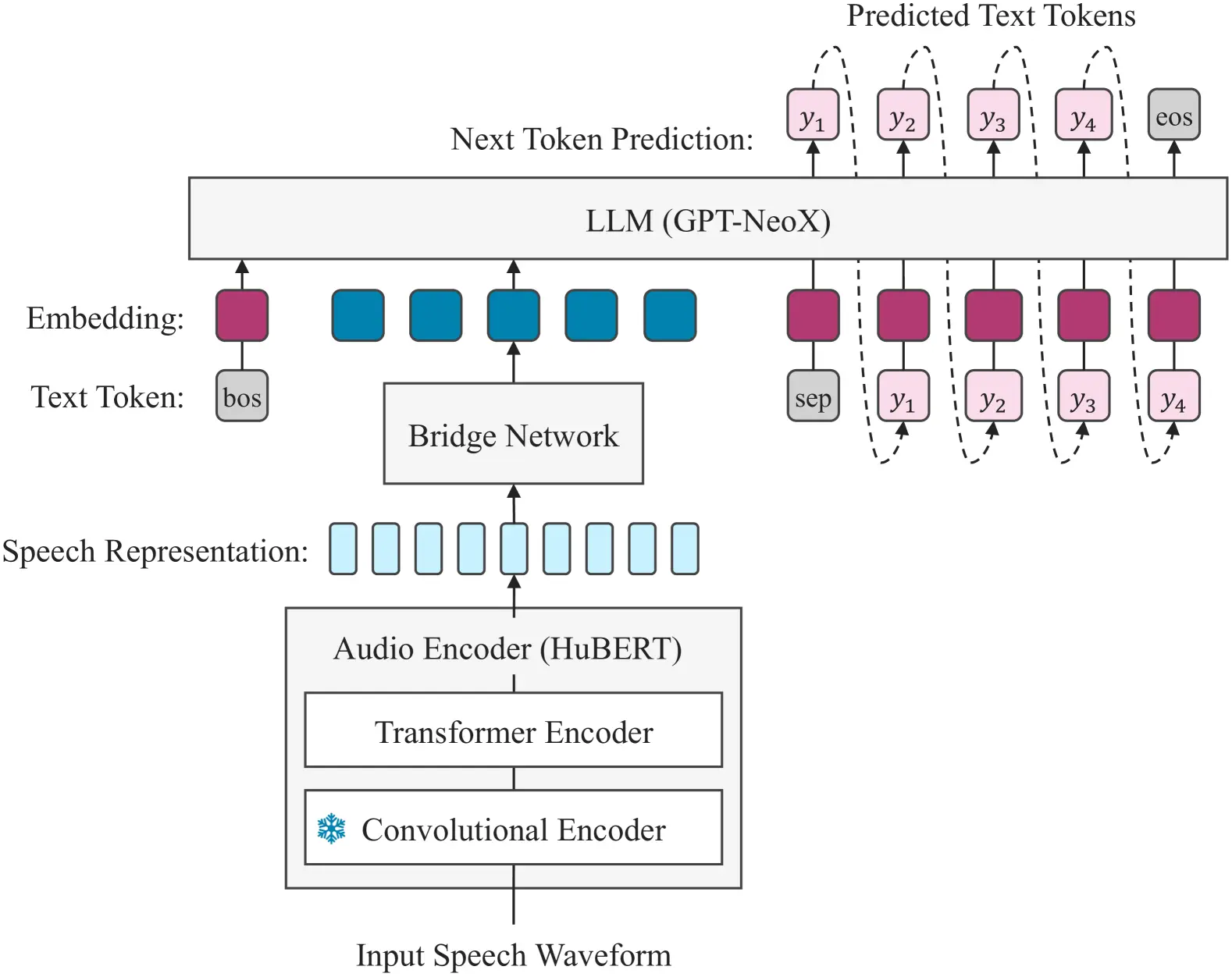
The image above is a schematic representation of a language model architecture that integrates both text and speech inputs for processing. It includes several components:
1. Input Speech Waveform: The raw audio input to the model.
2. Transformer Encoder and Convolutional Encoder: These further process the audio data after it has been encoded by HuBERT.
3. Audio Encoder (HuBERT): This part of the model processes the audio data.
4. Bridge Network: A component that connects the text processing part of the model with the audio representation part.
5. LLM (GPT-NeoX): The large language model component, likely responsible for generating text predictions.
6. Predicted Text Tokens: A sequence of tokens generated by the model, with ‘eos’ indicating the end of a sentence.
How can LLMs improve ASR accuracy?
1) Data Augmentation
Synthetic speech produced using LLMs can imitate many accents, speaking styles, and loud surroundings. By using this fake data to augment real training datasets, ASR models can be strengthened against speech variances found in the real world.
Consider training an ASR system to handle phone calls from customers. By producing synthetic speech with various accents and contact center-like background noise, LLMs could enhance the model's comprehension of actual client calls. Here is a research paper for further information. (Link)
2) Language Context
Large volumes of text data are used to train LLMs, which enables them to understand complex linguistic nuances and context. This contextual information can be integrated into ASR to help the model interpret spoken language more effectively.
Consider the sentence "Turn off the lights". An ASR system driven by LLM may examine the surrounding text or conversation history to determine whether this is a reference to headlights on an automobile, stage lights during a play, or bedroom lights.
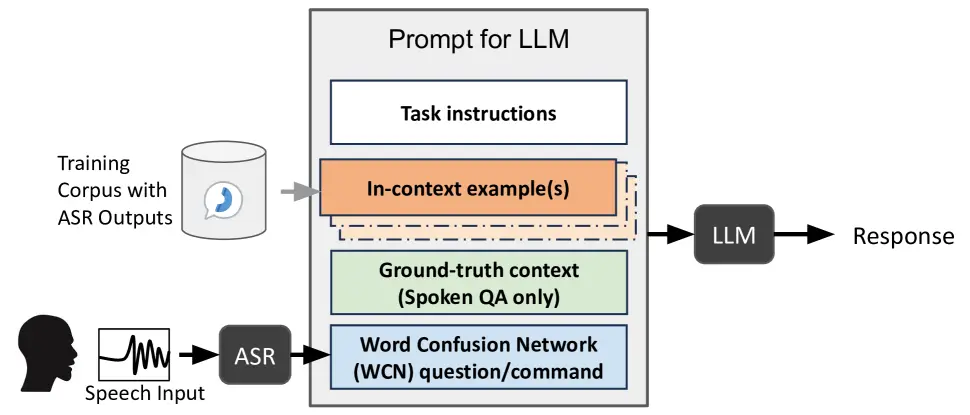
For Spoken Language Understanding (SLU), an in-context learning framework utilizing a transcript of a WCN question is proposed in the image above.
1. Speech Input: The process begins with a speech input that is fed into an Automatic Speech Recognition (ASR) system.
2. ASR System: Represented by a cylinder icon, the ASR system processes the speech input.
3. Training Corpus with ASR Outputs: The output from the ASR system is a training corpus that includes the ASR outputs.
4. Word Confusion Network (WCN) Question/Command: This step involves a WCN that processes the question or command from the training corpus.
5. Ground-truth Context: For spoken QA only, there’s a ground-truth context that is considered.
6. In-context Example(s): Both the WCN question/command and the ground-truth context feed into in-context examples, which are crucial for the LLM’s response generation.
7. Task Instructions: Above the in-context examples, there are task instructions that also contribute to the LLM’s processing.
8. LLM: Finally, all the information and instructions are processed by the LLM, which generates the response.
3) Adaptation to User Speech Patterns
Based on a user's unique voice data, LLMs can be adjusted (if available). By doing this, the LLM is able to pick up on the user's speech patterns and modify the ASR model to increase accuracy.
Imagine if your accent makes it difficult for your voice assistant to understand your requests. To improve speech recognition, LLMs can customize the ASR based on your previous conversations with assistance. See video-
How To Integrate LLM with ASR?
Let's examine the ways in which scientists are combining LLMs and ASR to achieve unparalleled accuracy and interpretation.
1) Two-Stage Processing
The ASR system takes the lead in this instance and converts the voice to text. The LLM receives this raw output and uses its extensive knowledge base to analyze it for grammar, context, and deeper meaning.
By doing so, the LLM is able to improve their understanding of the spoken language, possibly fixing mistakes and determining the speaker's intention.
2) Joint Training
This method feeds voice and text data into a single system that houses the LLM and ASR systems. Together, during training, the LLM gains an understanding of how speech is translated into text, which enhances its comprehension of the meaning and context of the sounds. You can find the link for the paper here.
Despite being computationally costly, this method can result in a more comprehensive and reliable understanding of spoken language.
3) Attention Mechanisms
In this case, LLM and the ASR system operate in conjunction. The ASR uses the audio input to determine possible words or sentences. After that, the LLM examines these choices in the context of the surrounding discourse and its linguistic comprehension. You will find the link for the paper here.
As a result, the LLM is able to direct the ASR system toward more precise and insightful speech interpretations.
4) Language Model Scoring
Using this method, the ASR system produces several transcriptions that it may provide for a specific speech segment. After that, the LLM takes over. It evaluates each choice and assigns a score according to how well it understands language grammar and context.
The transcription that receives the highest score is thought to represent the speech in the most natural and significant way.
Challenges of Integrating ASR With LLM
1) Computational Complexity
LLM and ASR require a lot of computing power. When combined, they can significantly raise the processing power needed, which makes real-time apps more difficult to run on devices with constrained resources.
Solution-
Model optimization can be utilized to solve this problem by reducing the size and processing footprint of ASR and LLM models while retaining high accuracy. Techniques like model pruning and quantization can be implemented to achieve this.
2) Data Quality and Bias
Training data plays a critical role in ASR and LLM performance. Combining these models may raise training data biases or limits. When dealing with accents, dialects, or speech patterns that are not sufficiently reflected in the data, this can result in errors.
Solution-
1. Data Augmentation - The artificial generation of more diverse training data using noise injection, speech synthesis, and speech scrambling can enhance the flexibility of ASR and LLMs to various accents, dialects, and speech patterns.
2. Continuous Learning - Constantly adding fresh data to ASR and LLM models enables them to gradually remove bias and adjust to evolving language patterns.
3) Error propagation - Errors can occur in ASR models. When these errors are sent into an LLM, the LLM might not be able to effectively fix them, leading to even more inaccurate output.
Solution-
Confidence Scoring
The LLM can prioritize accurate information while limiting potentially inaccurate results by giving confidence levels to ASR outputs.
4) Privacy concerns
Speech data may contain sensitive information. Concerns regarding possible privacy violations arise when integrating ASR with LLMs, especially during in-person encounters. Adhering to data privacy regulations and putting powerful anonymization mechanisms into practice are essential.
Solution-
Federated Learning is a technique that enhances privacy by training ASR and LLM models on decentralized datasets without directly exchanging sensitive speech data.
How are Companies Leading The Way With LLM-Enhanced ASR?
1) Customer Care
Businesses like Microsoft (Azure Bot Service), Amazon (Lex), and Google (Dialogflow) use LLMs to create chatbots and virtual assistants (like Alexa and Siri) who can interpret complicated queries, reply conversationally, and customize interactions.
2) Call Support
Call centers are integrating LLMs to automate operations including call routing, conversation transcription, and giving agents real-time summaries. Agent productivity can be increased and customer issues can be resolved more quickly as a result.
A company called VoiceOwl is revolutionizing call centers by merging standard ASR with LLMs. They provide AI-driven contact center solutions that make use of LLMs to enhance customer feedback and produce advantageous results for contact center managers.
By offering automated call routing, real-time transcriptions, and summaries, their technology helps call centers operate more efficiently, which results in more productive agents and faster customer service.
3) Booking Hotels
LLMs are used by travel agencies such as Booking and Expedia to facilitate voice-based hotel reservations. Contextual knowledge enables LLMs to comprehend user preferences, find relevant hotels, and finish bookings more accurately.
4) Safety and Security
A mobile phone company created especially for kids called Gabb Wireless. They filter messages for offensive material using a set of open-source models from Hugging Face. By doing this, kids are better shielded from inappropriate language and interactions with strangers.
5) Media & Entertainment
LLM-Enhanced ASR is being used by media companies to translate and subtitle live broadcasts in real-time. This not only increases viewer engagement in multiple languages but also makes content more accessible to non-native speakers.
A cloud-based solution that combines ASR with LLMs for real-time captioning and translation of live broadcasts and events is provided by SyncWords. They make live streams and events more accessible and interesting for a worldwide audience by offering automatic live subtitles in more than 100 languages.
Their software provides instantaneous language scaling for live events and live streams, and it facilitates smooth integration with many video streaming protocols. By offering precise automatic foreign subtitles for any live video material, from conferences and business meetings to sports and news, SyncWords technology aims to improve the viewing experience.
Current Trends With ASR
The growing amount of data and improvements in neural network architectures are driving a rapid evolution of the ASR. Modern ASR systems are improving in accuracy as well as in their ability to accommodate a wider range of languages and dialects.
In particular, the merging of ASR with LLM allows for naturalistic and context-aware interactions. This collaboration is making it easier for ASR technologies to be integrated into a wide range of applications, such as virtual assistants and real-time transcription services, which will transform how humans interact with both machines and one another.
Here is the list of the best tools for ASR.

Voice assistants and smart speakers
Amazon Alexa, Google Home, and Apple Siri are just a few examples of devices that use artificial speech recognition to make everyday chores more convenient for users.
These devices allow users to do things like play music, create reminders, manage smart home devices, and access information with voice requests.
Speech-to-Text Transcription
Automatic speech recognition (ASR) technology is used in a variety of professional contexts to convert spoken language into written text, supporting the documenting of meetings, court cases, and medical records. The accuracy and productivity of documentation processes are improved by this program.
Voice Search and Dictation
Using voice search on smartphones and other devices, users may compose emails, send messages, and search the web without using their hands. ASR is also used by word processors' dictation features to translate spoken words into text, increasing productivity and accessibility.
Interactive Voice Response Systems (IVRS)
Organizations can handle customer support calls, forward calls to the relevant departments, and offer automated support using IVRS powered by ASR. These systems shorten wait times and facilitate natural-language conversations, improving the customer experience.
Automatic Captioning and Subtitling
Videos, live broadcasts, and online content are all captioned and subtitled in real time using ASR technology. This increases the usability of multimedia content for a wider audience and makes it more accessible to people with hearing problems.
Challenges and Limitations of ASR
Although automatic speech recognition (ASR) has advanced significantly, there are still a number of issues that prevent it from fully comprehending spoken language.
Background noise and Speech Variations
ASR systems frequently have trouble in noisy settings or with voices that overlap. The accuracy of voice recognition can be severely reduced by background noise, which makes it more challenging for the system to understand commands.
Speech variations, such as shifts in intonation, pitch, and speed, provide additional difficulties and might result in transcription and comprehension mistakes.
Accurately Capturing Accents and Dialects
The inability of modern ASR technology to accurately detect and analyze a wide range of accents and dialects is one of its main drawbacks. Because standard language datasets are used to train most ASR systems, users with non-standard accents or regional dialects may experience lower accuracy.
This restriction has an impact on the usefulness of voice recognition systems and their inclusivity for a worldwide user base.
Privacy Concerns and Security Considerations
Due to the fact that voice data must be frequently processed and stored, sometimes on external servers, the use of ASR technology presents serious privacy concerns. This gives rise to concerns about misuse of personal data, illegal access, and data breaches.
Gaining user trust and adhering to rules require addressing crucial challenges, including ensuring the security of voice data and putting in place strong privacy protections.
The Future of ASR
Constant Enhancement of Precision and Effectiveness
ASR accuracy and processing speed will continue to improve thanks to developments in AI and machine learning. Deep learning, neural networks, and real-time data analysis are some of the techniques that will help ASR systems handle complicated speech patterns more skillfully, grasp context better, and make fewer mistakes.
Enhancing ASR's robustness and reliability will also require ongoing training with a variety of datasets.
Growth into New Sectors and Applications
ASR technology has the potential to go beyond conventional uses such as virtual assistants and customer support. ASR will be widely used in emerging industries, including healthcare, where it can help with medical record transcription, and automotive, where voice-activated navigation devices are available.
ASR will also be integrated by the financial, education, and entertainment sectors to improve user experiences, streamline operations, and offer cutting-edge services.
Seamless Human-Computer Interaction (HCI) Integration
In order to create more logical and natural user interfaces, ASR will need to integrate with other HCI technologies on a deeper level in the future. To provide a comprehensive interaction experience, voice recognition will be integrated with gesture controls, visual recognition, and other multimodal inputs.
This will make it possible for humans and machines to communicate more easily, improving technology's usability and accessibility across a range of platforms and devices.
How to improve your ASR models with Labeller
The most recent update from Labellerr brings an effective tool for fine-tuning already-existing ASR models. With the help of this new capability, users can iteratively modify model parameters based on particular use cases and datasets, improving the accuracy and efficiency of ASR systems.
Labellerr facilitates targeted enhancements to ASR models by giving users a streamlined interface for annotating and labeling audio data. This allows users to mark transcripts precisely and improve the mistakes of ASR models.
This capability not only improves transcription quality but also speeds up the creation of more resilient and flexible ASR solutions that can be customized for a wide range of applications and sectors.
Users directly connect raw audio with ASR-generated output on which Labellerr's language expert improves the accuracies by removing misheard words and putting unheard words back into the transcription.
LLM-powered captioning also helps language experts to verify the transcript in real-time.
Conclusion
Since its beginning, ASR has come a long way, from simple digit recognition to advanced systems capable of handling continuous speech with amazing accuracy in a variety of contexts and accents.
ASR has undergone even more transformation with the advent of Large Language Models (LLMs), which provide context understanding, error correction, and domain-specific knowledge. Prominent companies are employing LLM-enhanced ASR for a range of uses, such as call help, hotel reservations, and customer support.
Because of the combination of ASR and LLMs, human-computer interactions will be more accessible, intuitive, and natural in the future, which bodes well for the field of ASR. The technology known as Automatic Speech Recognition (ASR) translates spoken words into text.
While deep learning is employed in modern systems, such as RNNs and CNNs trained on enormous datasets, early models rely on statistical techniques. This makes it possible to recognize continuous speech accurately in a variety of settings and dialects.
FAQ
Q1) What is ASR and how does it work?
Automatic Speech Recognition (ASR) is a technology that converts spoken language into text. Early models used statistical methods, but modern systems leverage deep learning like RNNs and CNNs trained on massive datasets. This enables accurate recognition of continuous speech across accents and environments.
Q2) What's the role of language models in ASR?
Language models (LMs) aren't directly involved in converting speech to text, which is the core function of ASR's acoustic models. LMs come in after the initial speech recognition step, acting as post-processing tools. They analyze the list of possible word sequences generated by the acoustic model and score them based on their likelihood of being correct and grammatically sound in the given context.
Q3) What types of language models are used in ASR?
Several types of LMs can be employed in ASR, with n-gram models being the most common:
1. N-gram Models: These models predict the probability of a word based on the n-1 preceding words. For example, a trigram model considers the previous two words to predict the next most likely word.
2. Statistical Language Models: These models leverage statistical analysis of vast text datasets to learn word probabilities and relationships.
3. Neural Language Models (NLMs): These advanced models use deep learning, particularly recurrent neural networks (RNNs), to capture complex word relationships and contextual information.
Q4) How do language models improve ASR accuracy?
By considering language context, LMs offer several benefits:
1. Reduced Word Error Rate (WER): WER is a common metric for ASR accuracy. LMs help filter out unlikely word sequences, leading to a lower WER and more accurate speech recognition.
2. Improved Handling of Ambiguity: In cases where the acoustic model generates multiple word possibilities, LLMs consider surrounding words to identify the most likely sequence, especially helpful in noisy environments or ambiguous pronunciations.
3. Domain-Specific Adaptation: LLMs can be trained on data specific to a particular domain (e.g., medical terms for healthcare). This improves accuracy in scenarios where specialized vocabulary is used.
References
1. An Embarrassingly Simple Approach for LLM with Strong ASR Capacity(Link)
2. Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages(Link)
3. Towards ASR: Robust Spoken Language Understanding Through In-Context Learning With Word Confusion Networks(Link)

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
