

Meta Releases SAM & It's Going To Change Data Labeling


Segmentation, the process of extracting relevant parts of an image, is a crucial but complex task that has many practical applications. For example, in cameras, segmentation is used to create beautiful portrait mode shots, which differentiate between the foreground (object of interest) and the background using segmentation.
However, creating applications that rely on segmentation typically requires collecting relevant data and annotating images with masks to indicate the relevant parts. As the complexity of the application increases, so does the cost of the annotation skills required. For instance, annotating data to segment humans from images is less costly than annotating data to segment cancerous cells from images.
But with the release of a model like SAM , developers can create new applications that rely on segmentation at an unprecedented pace.
What is Segment Anything Model (SAM)
The Dataset that is used to train SAM is also released by META ,it consists of 11 million images, with an average of 100 masks per image. Labels of the masks are class agnostic that is they are provided binary values instead of actual name of the object . Due to this they are able to provide masks which can give two different mask for the human body and human leg quite well.

According to the Dataset Card provided by meta the images were processed to blur faces and licensed plates .
Overview on the model working
SAM is said to be trained on over 1 billion masks having almost 11 million images, the model is trained such that it can accept various prompts that is a bounding box, a text or even a point . SAM is a zero-shot model which means it can generate segments even for the categories of images on which it wasn't trained . According to the paper released by meta they claim "That its zero-shot performance is impressive – often competitive with or even superior to prior fully supervised results."
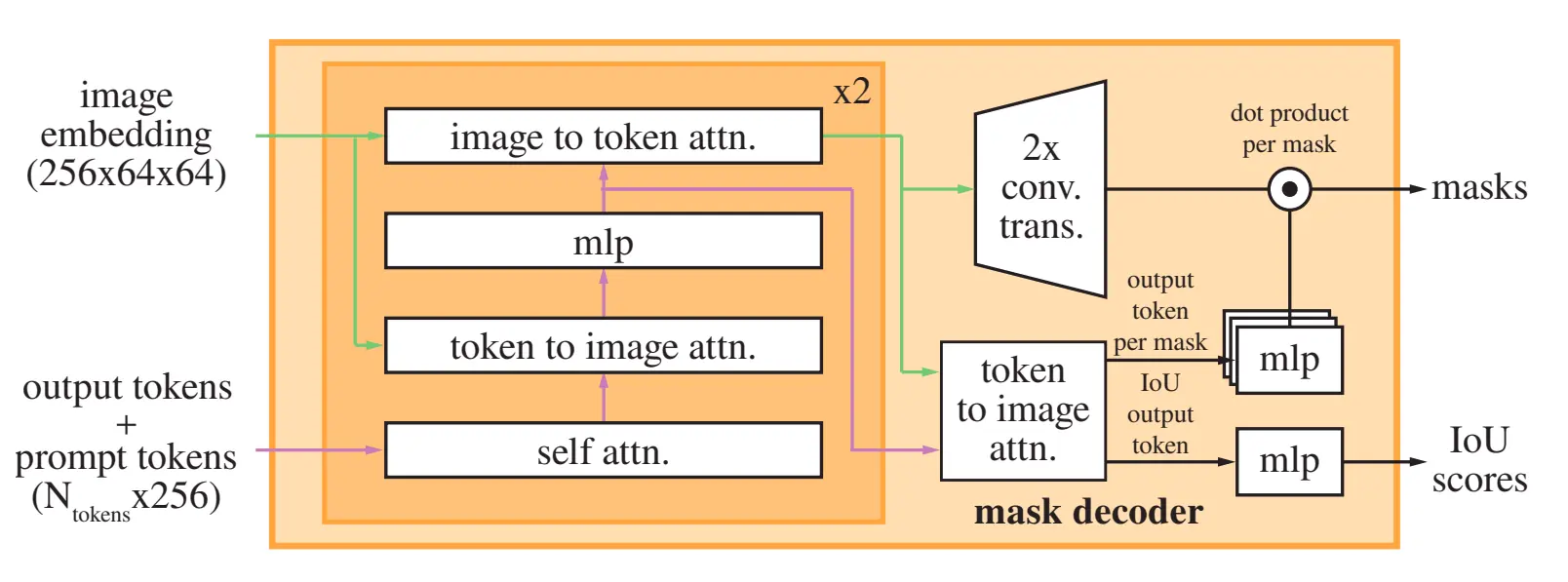
SAM comprises of 3 models a powerful image embedding model which stores your image embedding such that you can generate different masks on the image number of times without generating image embeddings repeatedly . The second model is a prompt encoder model which encoded prompt of different types such as texts, bounding boxes and points . The last model is a lightweight mask decoder that predicts the masks based on the combined information of both encoders.
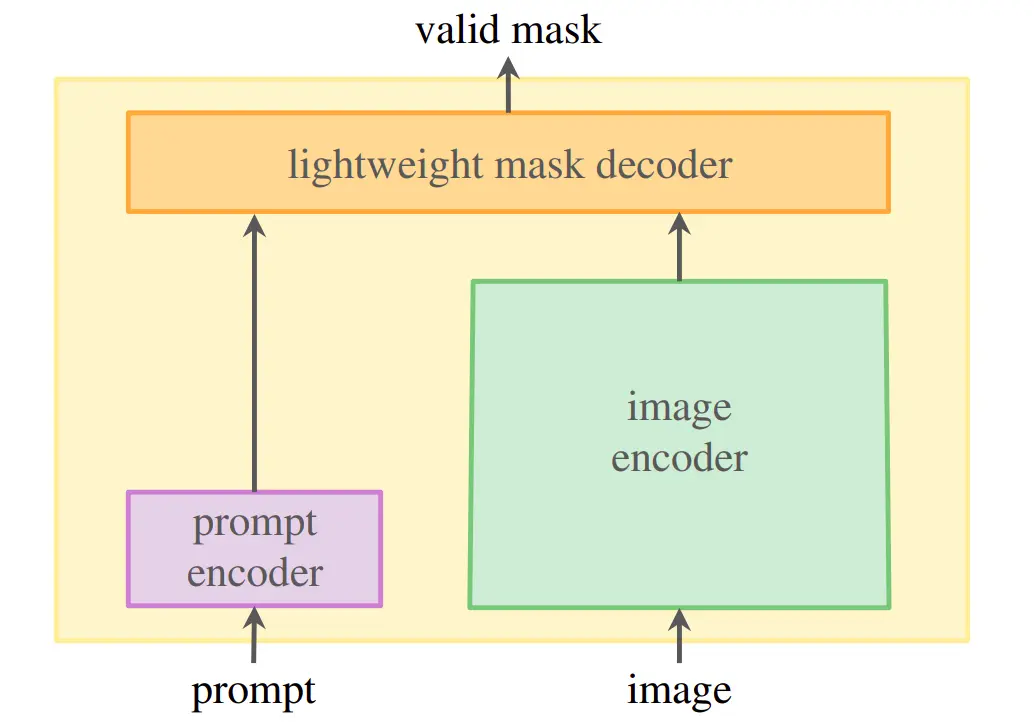
To generate the image embedding they use an Masked Auto Encoders (MAE) pre-trained Vision Transformer(ViT) which is adapted to process high resolution inputs as well. This encoder runs once per image and can be applied before prompting the model .
The Prompt encoder model accepts two different sets of prompts one is of sparse type (points, boxes, and text) and the other is of dense type (masks ).The Light Mask decoder model used in SAM can generate mask in ~50ms, given the encoded prompt and the image embedding .
Demonstration
Meta released codebase to implement SAM on github along with the weights of the model. Currently the released codebase supports two types of prompts that is points and bounding box based prompts which you can combine and send it together as well . I tried to implement the model on the following image for point based prompt and these were the outputs .

The Input prompt , green star indicating the input point for which I would like to generate masks . The masks that are generated are as follows



As they also mention in the paper that for each abrupt prompt the model generates various masks having different confidence score and , since a point is an abrupt prompt and it doesn't exactly indicates that what segment we want it has generated the top three best segments . You can further use these masks and generate a more refined mask by giving other prompts for example in the image I decided to separate foreground and background based on the points and gave each point a label 1 and 0, where 1 indicates foreground and 0 indicates background in the image the red star is background and green star is foreground.

The output generated for the image is

The output that is returned by the model is masks, logits and also scores or confidence score for each mask . If you want to give box as a prompt the format needs to be XYXY format , indicating xmin, ymin, xmax, ymax for bounding box.
The other way to use SAM is to generate segmentation on the whole image automatically without specifying any particular prompt , I tried it for the same image and here are the results .

For this type of prediction the model returns masks, area of mask in pixels, bounding box in XYWH format , predicted_iou, stability_score an additional score they measure for the mask quality and the crop box which is used to generate the masks in XYWH format.
The Revolution
Currently inorder to annotate the segments it's a huge time consuming task which takes annotators quite a lot of time to draw the polygons point wise and label each polygon get them reviewed although thanks to SAM , we can reduce the time taken to draw polygons and help the annotators label the segments quickly , along with this since we also get confidence scores for each mask that is generated it will help reviewers to quickly identify the images they should review first and thus reducing the time to generate quality data for model training .
Limitations of the model
But there's a problem , the weights of SAM are above 2GB , moreover it takes quite a lot of time to generate the image embedding for each image higher the resolution more time it takes to generate the embedding for images the time can vary from 2 min to even 15 to 20 mins , which is quite a lot of time for a tool to simply get the polygon segments on the image.
On top of this model creates too many masks in each image even if the object is a single object but it can create multiple masks which requires more editing to the polygon
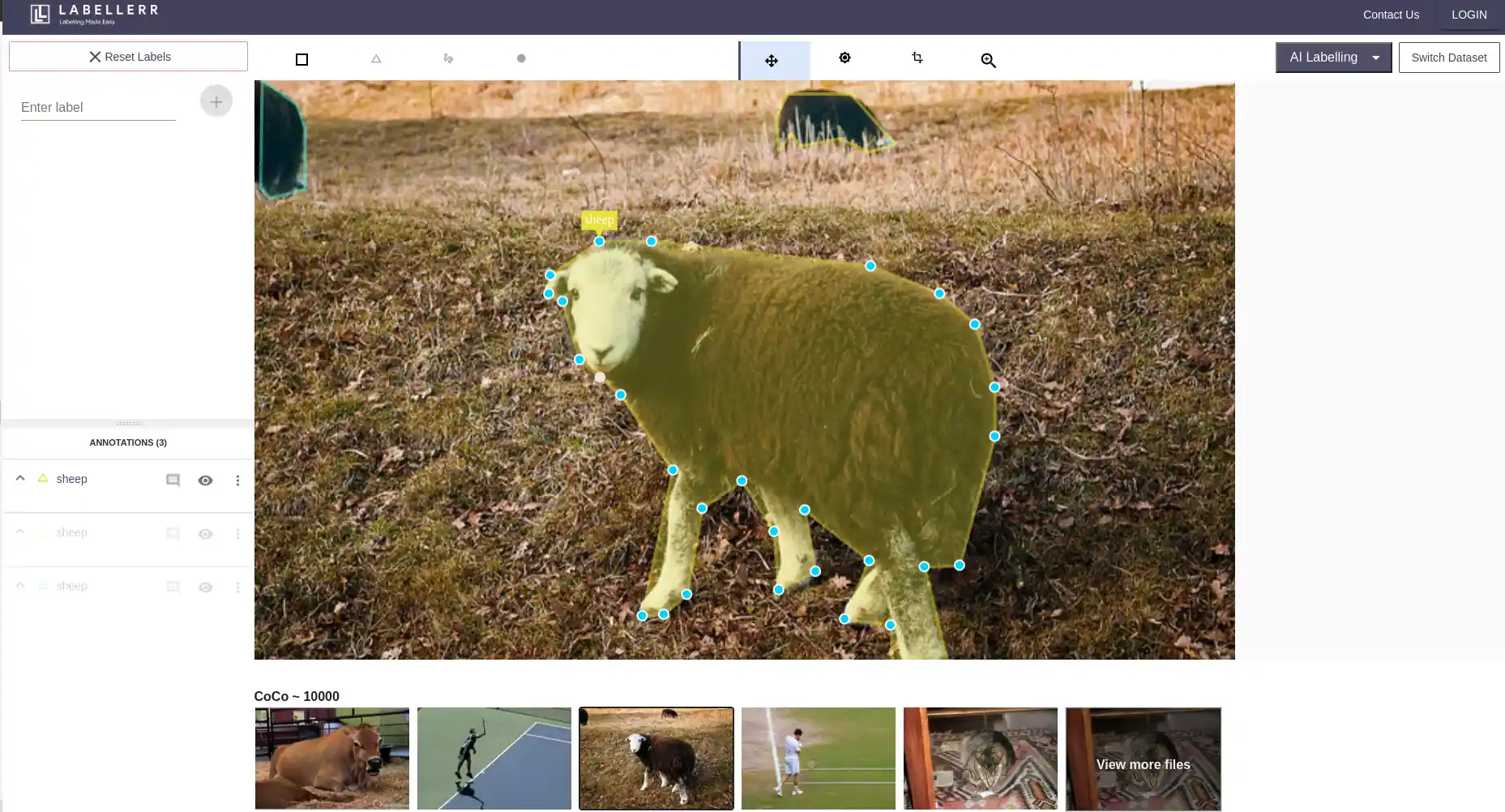
We at Labellerr help AI Organisations to easily prepare the data for problem statements such as segmentation , object detection and classification . We are able to truly automate the flow of annotating the segments in image with the help of multiple foundation models to reduce the annotation efforts for data preparation.
Here's a sample snapshot of detection of sheep's from the image, to get the polygons and segmented masks of each sheep .

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
