

Elevating ML: AI-Driven Data Annotation with LabelGPT


Table of Contents
- Introduction
- Pre-requisite Concepts for Automated Data Labelling
- About Foundation Models
- Overview of Zero-Shot Learning and Its Role in Automated Data Labeling
- Generative AI-Powered Prompt-Based Data Labeling
- LabelGPT
- How LabelGPT Works
- Benefits of LabelGPT
- Conclusion
- Frequently Asked Questions (FAQ)
Introduction
Data labeling is a crucial step in the process of training machine learning and artificial intelligence models. It involves annotating or tagging data samples to provide meaningful and accurate information that can be used to train algorithms.
Data labeling helps machines understand and interpret the data they receive, enabling them to make informed decisions and predictions.
Figure: Data Labelling
It includes assigning specific labels or tags to different elements within a dataset. Depending on the project's specific requirements, these labels could be various types of information, such as categories, classes, attributes, or annotations.
For example, in image recognition, data labeling involves marking objects, drawing bounding boxes around them, or assigning specific labels to each object present in the image.
Human annotators can perform the data labeling process manually or through automated techniques using pre-defined rules or algorithms. Manual data labeling often requires human expertise and judgment to interpret and annotate the data accurately.
On the other hand, automated data labeling techniques leverage pre-existing labeled datasets or algorithms to generate annotations automatically.
Data labeling is essential because it provides ground truth or reference data that machine learning models use during training.
The accuracy and quality of the labeled data significantly impact the performance and reliability of the trained models. Therefore, careful attention must be given to ensure consistency, accuracy, and reliability in the data labeling.
Various types of data require labeling, including images, videos, text, audio, sensor data, and more. Each type of data may have its specific labeling requirements and techniques. For instance, in text classification, data labeling involves assigning predefined categories or tags to different text documents or segments.
Data labeling is time-consuming and resource-intensive, particularly when dealing with large datasets. It often requires domain expertise and human annotators who can understand the context and intricacies of the data.
However, technological advancements, such as semi-supervised learning and active learning techniques, aim to reduce the manual effort required for data labeling.
Pre-requisite Concepts for Automated Data Labelling
To understand how LableGPT works, there are certain Prerequisite concepts that one needs to be familiar with. In this section, we briefly discuss these concepts and go into detail in further sections.
1. Learning Techniques
There are various different learning techniques that are used by machine learning models. In the below section, we discuss these in detail.
i) Supervised Learning
Supervised learning is a technique in machine learning that depends on datasets with labeled information to teach algorithms how to accurately classify data or make predictions about outcomes. By using labeled inputs and outputs, the model can assess its performance and improve over time.
Figure: Supervised Learning
Supervised learning can be classified into two main types: classification and regression. In classification problems, algorithms are employed to assign test data to specific categories accurately.
For instance, they can distinguish between apples and oranges or classify spam emails into separate folders. Common supervised machine-learning algorithms include linear classifiers, support vector machines, decision trees, etc.
Regression, on the other hand, is a supervised learning method that focuses on understanding the relationship between dependent and independent variables.
Regression models are useful for predicting numerical values based on different data points, such as projecting sales revenue for a business. Linear regression, logistic regression, and polynomial regression are popular regression algorithms used in such scenarios.
ii) Unsupervised Learning
Unsupervised learning involves the use of machine learning algorithms to analyze and cluster unlabeled datasets, enabling the discovery of hidden patterns without human intervention.

Figure: Unsupervised Learning
These models are applied to three major tasks including clustering, association, and dimensionality reduction.
Clustering is a data mining technique that groups similar unlabeled data based on their similarities or differences.
For instance, K-means clustering algorithms assign data points with similarities to groups, with the "K" value determining the granularity and size of the clusters. Clustering finds applications in market segmentation, image compression, and more.
Association, another type of unsupervised learning, identifies relationships between variables in a given dataset using different rules. These methods are commonly utilized in market basket analysis and recommendation engines, such as generating "Customers Who Bought This Item Also Bought" recommendations.
Dimensionality reduction is a learning technique employed when the number of features or dimensions in a dataset is excessively high. It reduces the dimensionality of input to a manageable size while preserving data integrity.
Dimensionality reduction is often used in preprocessing stages, such as when autoencoders remove noise from visual data to enhance image quality.
iii) Semi-Supervised Learning
Semi-supervised learning is machine learning which is an intermediary of supervised and unsupervised learning. It utilizes a combination of labeled and unlabeled data to train models. In semi-supervised learning, a small portion of the data is labeled, while the majority remains unlabeled.
The key idea behind semi-supervised learning is that by leveraging both labeled and unlabeled data, models can improve their performance compared to using just labeled data or unsupervised methods alone.
The labeled data provides explicit supervision for the model, while the unlabeled data provides additional information and aids in capturing the underlying structure or patterns in the data.
One common approach in semi-supervised learning is to propagate the labels from the labeled instances to the unlabeled instances based on their similarity or proximity in the feature space. This allows the model to utilize the unlabeled data to refine its predictions and decision boundaries.
One real-life example of semi-supervised learning in computer vision is in the field of autonomous driving and perception systems. Autonomous vehicles rely on computer vision algorithms to understand their surroundings and make informed decisions. However, manually labeling large-scale datasets for training such algorithms can be expensive and time-consuming.
In this scenario, semi-supervised learning can be employed to leverage both labeled and unlabeled data to train perception models for object detection or semantic segmentation tasks. For example, consider the task of pedestrian detection.
iv) Reinforcement learning
Reinforcement learning is a branch of machine learning that focuses on an agent learning how to make decisions or take actions in an environment to maximize a reward signal. It is inspired by the way humans and animals learn through trial and error.
In reinforcement learning, an agent interacts with an environment and receives feedback in the form of rewards or punishments based on its actions. The goal of the agent is to learn an optimal policy—a mapping of states to actions—that maximizes the cumulative reward over time.
The 5 major components of reinforcement learning are:
- Agent: The entity that takes actions in the environment based on a policy.
- Environment: The external system with which the agent interacts and receives feedback.
- State: The current representation of the environment at some given time.
- Action: The action of the final decision made by the agent.
- Reward: The feedback signal provided by the environment to indicate the desirability of the agent's action.
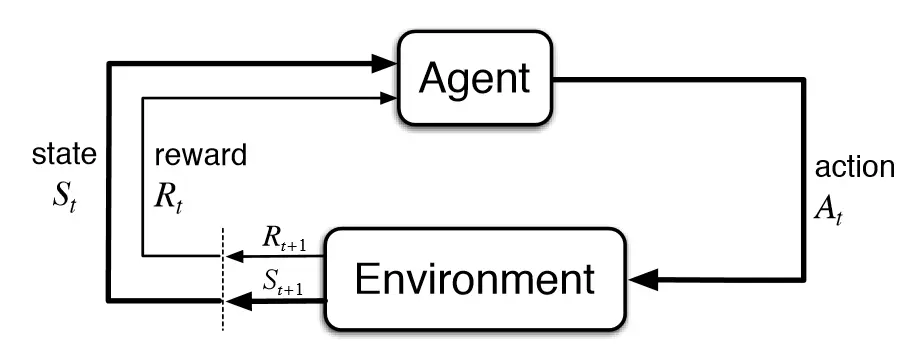
Figure: Reinforcement Learning
The agent learns through a trial-and-error process by exploring different actions, receiving rewards, and updating its policy based on the observed outcomes.
Reinforcement learning algorithms employ techniques such as value functions, Q-learning, policy gradients, and Monte Carlo methods to optimize the agent's decision-making process.
Reinforcement learning has been successfully applied to a variety of tasks, including game playing, robotics, autonomous vehicles, recommendation systems, and resource management.
It is particularly useful in situations where there is no explicit supervision or pre-existing labeled data but rather a reward signal that guides the learning process.
By combining exploration and exploitation strategies, reinforcement learning enables agents to learn optimal decision-making policies in dynamic and uncertain environments, making it a powerful paradigm for autonomous learning and decision-making.
v) Self-supervised Learning
Self-supervised learning extracts supervisory signals from the data itself, utilizing the inherent structure within the data. The approach involves predicting unobserved or hidden aspects of the input based on observed or unhidden parts.
For instance, in NLP, a sentence can be partially concealed, and the task is to predict the missing words using the remaining context. Similarly, in videos, future or past frames can be predicted from the current frames. By leveraging the data's internal structure, self-supervised learning can harness various supervisory signals across different modalities and large datasets, all without relying on labeled data.
The term "self-supervised learning" has gained acceptance over the previous term "unsupervised learning" because it better reflects the approach's nature. "Unsupervised learning" is a vague and misleading term that suggests a lack of supervision altogether.
In reality, self-supervised learning employs a more extensive array of feedback signals compared to traditional supervised and reinforcement learning methods.
vi) Federated Learning
Federated learning is a method in machine learning that enables multiple devices or entities to collectively train a shared model without the need to share their raw data with each other.
In traditional machine learning, data is collected from various sources, centralized in a single location, and then used to train a model. In federated learning, however, the training process takes place locally on the devices themselves, such as smartphones, edge devices, or IoT devices.
The devices train the model using their own local data while keeping the data on the device, thus preserving privacy and security.
2. Foundation Models
Foundation models play a crucial role in automated data labeling, providing a basis for understanding and processing raw data. These models are pre-trained on large-scale datasets and have learned to generate meaningful representations of various types of data, such as text, images, and audio.
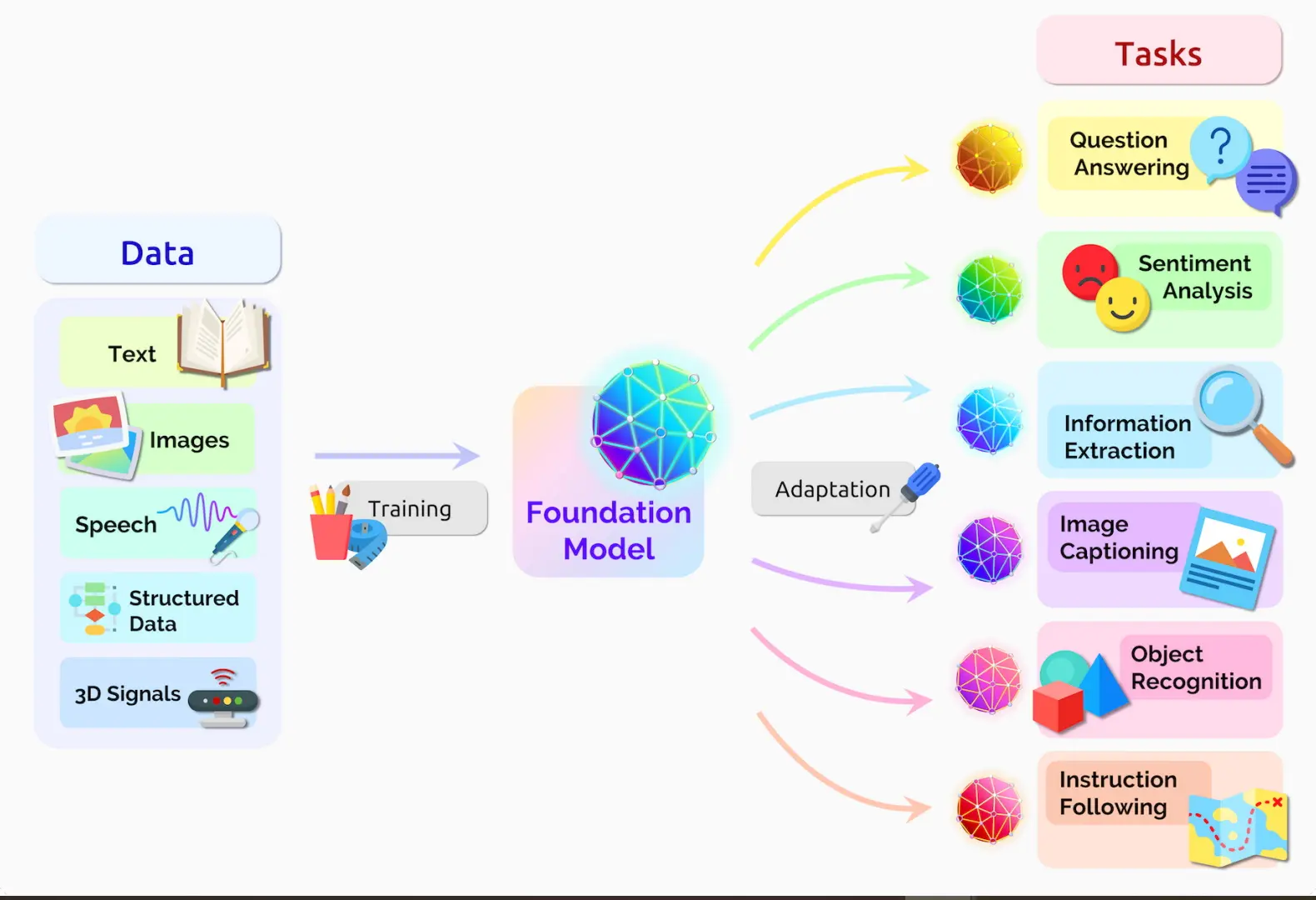
Figure: Foundational Models
They are powerful tools for automated data labeling by extracting relevant features and providing contextual understanding to make accurate predictions. There are several key foundation models used in automated data labeling across different domains:
i) Natural Language Processing (NLP) Models
These models, such as OpenAI's GPT (Generative Pre-trained Transformer) models, are pre-trained on vast amounts of text data. They capture semantic and syntactic patterns, allowing for tasks like sentiment analysis, named entity recognition, text classification, and text generation.
They are invaluable in automating the labeling of textual data, such as customer reviews, social media posts, or chat conversations.
ii) Computer Vision Models
Foundation models like convolutional neural networks (CNNs) pre-trained on large image datasets, such as ImageNet, are widely used for automated data labeling in computer vision tasks.
These models can extract visual features, recognize objects, detect faces, classify images, and perform image segmentation. They enable automated labeling of images and videos for applications like object detection, image classification, facial recognition, and scene understanding.
iii) Audio and Speech Recognition Models
Pre-trained models in the field of audio processing and speech recognition, such as WaveNet or DeepSpeech, are essential for automated data labeling in tasks like speech-to-text transcription, speaker identification, emotion detection, and speech sentiment analysis. These models learn to extract acoustic features and understand spoken language, enabling automated labeling of audio data.
3. Transfer Learning
Transfer learning plays a vital role in utilizing pre-trained foundation models for automated data labeling. Instead of training models from scratch, transfer learning allows for the reusability of pre-trained models by fine-tuning them on specific data or tasks.
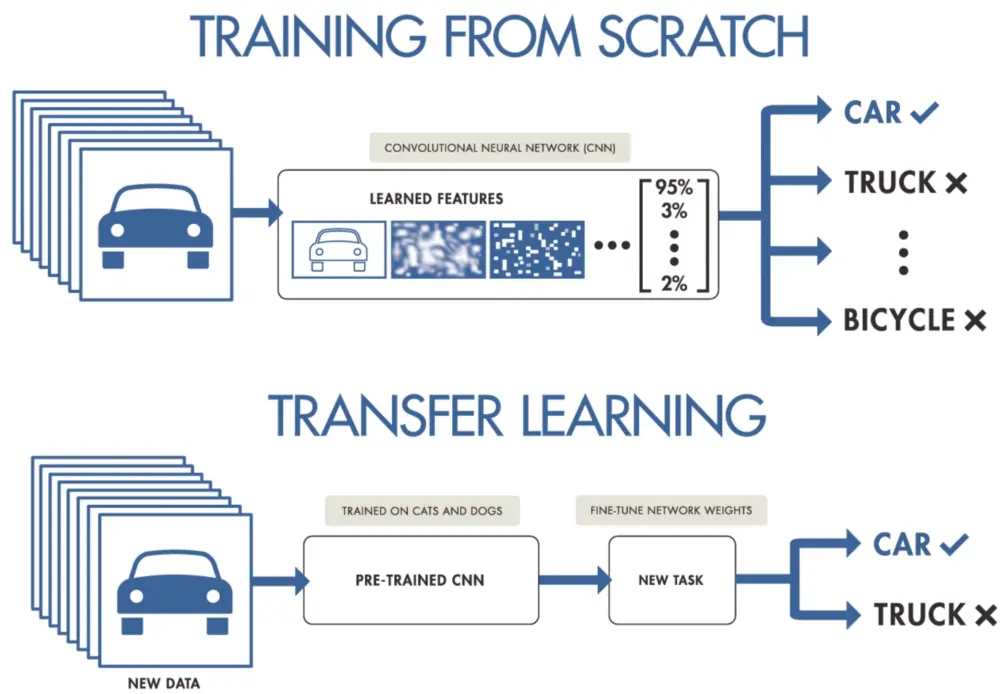 Figure: Transfer Learning
Figure: Transfer Learning
Figure: Transfer Learning
This approach leverages the knowledge and representations learned by foundation models, saving computational resources and improving labeling accuracy. By utilizing transfer learning, the pre-trained models can be adapted to perform automated labeling on domain-specific data, speeding up the labeling process and achieving higher-quality results.
4. Zero-shot learning
Zero-shot learning is an important concept in automated data labeling, where pre-trained models are used to label data outside their training distribution. It enables models to generalize and label data in new or unseen categories without explicit training examples.
This is particularly useful when dealing with evolving datasets or new classes that emerge over time. By leveraging the understanding and knowledge encoded in foundation models, zero-shot learning enables automated labeling in scenarios where manual annotation for every possible category is not feasible or efficient.
5. Prompt engineering
Prompt engineering is an important concept in automated data labeling that focuses on crafting effective prompts or instructions to guide the behavior of foundation models during the labeling process. It involves designing specific prompts that elicit the desired labeling behavior and helps produce accurate and consistent annotations.
Effective prompt engineering can significantly improve the performance and reliability of automated data labeling systems.
By carefully engineering prompts, the automated data labeling system can effectively guide the behavior of foundation models, leading to more accurate and reliable labeling.
Prompt engineering is an ongoing process that requires continuous refinement and adaptation based on the specific task, domain, and feedback from human annotators. It plays a vital role in ensuring the quality and consistency of the labeled data produced by automated data labeling systems.
About Foundation Models
Foundation models are large-scale artificial intelligence models that are trained on massive amounts of unlabeled data, typically using self-supervised learning techniques.
This training process enables these models to acquire a broad range of capabilities, including tasks like image classification, natural language processing, and question-answering, with impressive accuracy.
These models excel at tasks that involve generating content in collaboration with human input, such as writing marketing copy or creating detailed artwork based on simple prompts.
However, there are challenges when it comes to adapting and deploying these models for enterprise use cases. When a task exceeds the capabilities of a foundation model, it may generate incorrect or fabricated outputs that appear as plausible as correct responses, often referred to as "hallucinations."
Foundational Models in Different Domains
Foundation models are typically trained using unsupervised or self-supervised learning approaches, where they learn to predict missing parts of the input or to reconstruct the original input from corrupted versions.
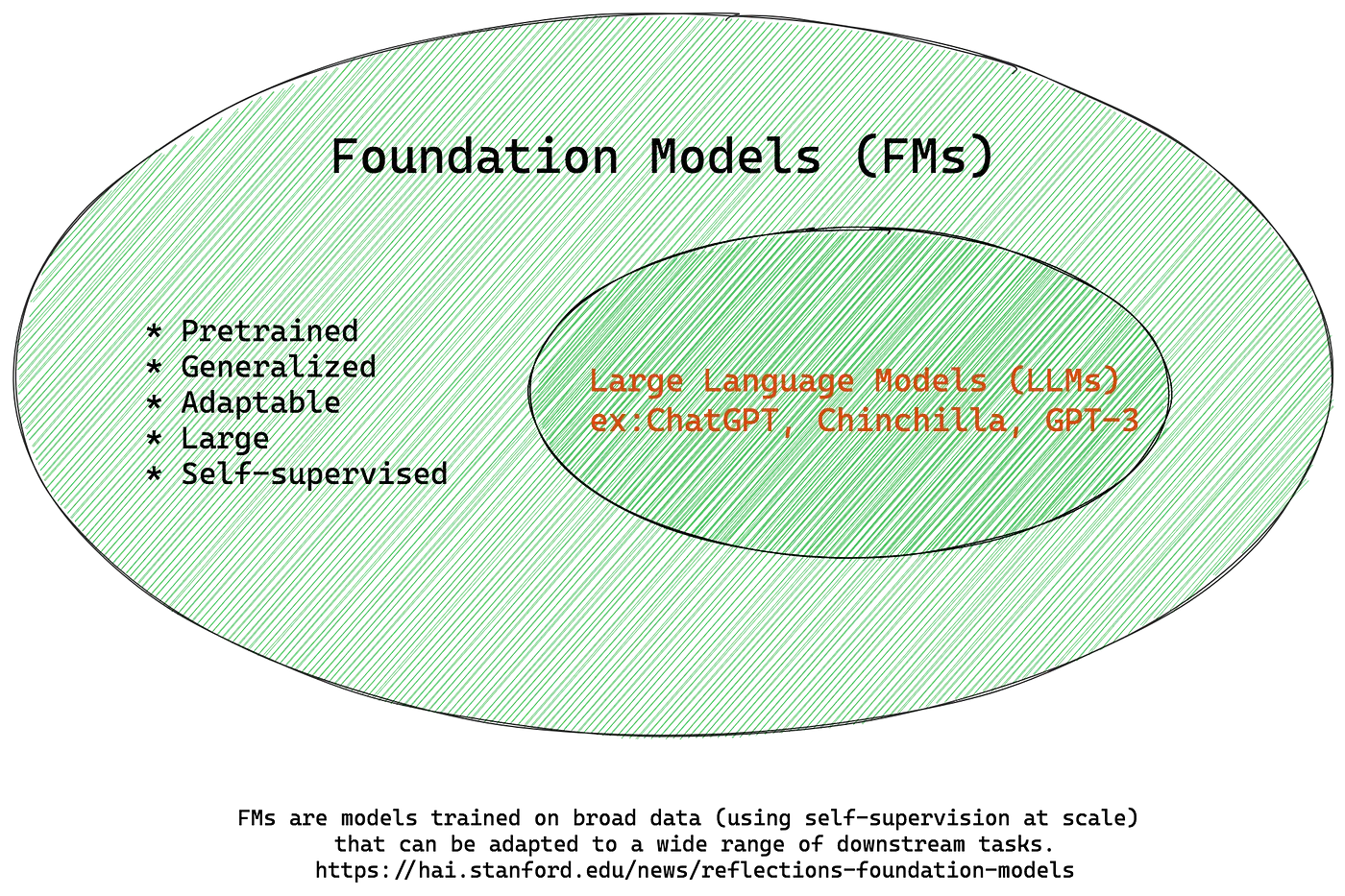 Figure: Foundation Models
Figure: Foundation Models
Figure: Foundation Models
This pre-training phase helps the models capture important patterns and representations in the data. Once pre-training is completed, these models can be fine-tuned on specific tasks with labeled data.
1. Natural Language Processing
In natural language processing, foundation models like GPT (Generative Pre-trained Transformer) or BERT (Bidirectional Encoder Representations from Transformers) have demonstrated remarkable performance on sentiment analysis, text classification, question answering, and machine translation tasks.
These models have learned contextual representations of words, sentences, and documents, enabling them to understand the semantics and syntax of natural language.
2. Computer Vision
In computer vision, foundation models like convolutional neural networks (CNNs), such as ResNet, VGG, or Inception, have revolutionized tasks like image classification, object detection, image segmentation, and facial recognition.
These models learn hierarchical representations of visual features, allowing them to recognize objects, understand spatial relationships, and extract meaningful information from images.
3. Audio Processing
In audio processing, foundation models such as WaveNet or DeepSpeech have made significant advancements in tasks like speech-to-text transcription, speaker identification, emotion detection, and speech sentiment analysis. These models capture acoustic features and learn to understand spoken language, enabling accurate labeling and analysis of audio data.
This transfer-learning approach saves significant computational resources and reduces the need for extensive labeled datasets. By fine-tuning the pre-trained models on task-specific data, they can quickly adapt to new domains and achieve high performance.
Furthermore, foundation models provide a starting point for automated data labeling. By leveraging their learned representations, contextual understanding, and prediction capabilities, these models can automatically generate annotations or labels for unlabeled data.
This automation speeds up the data labeling process, increases efficiency, and enables scalability in applications where manual annotation is time-consuming or expensive.
Foundation models in automated data labeling
Foundation models play a critical role in automated data labeling by providing the fundamental building blocks for the labeling process.
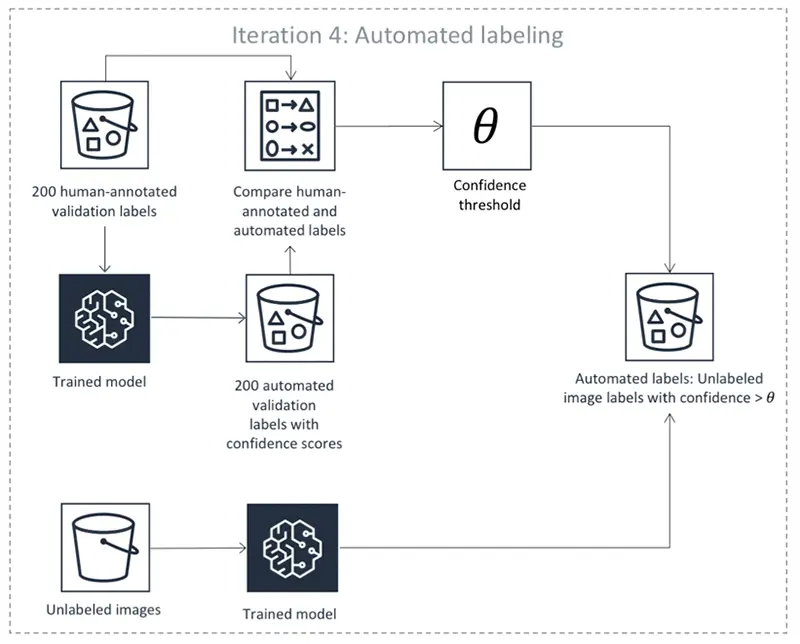
Figure: Automated Data Labelling
These models, which are trained on large-scale datasets using advanced machine learning techniques, offer several key contributions to automated data labeling.
One of the primary roles of foundation models is feature extraction. These models are capable of learning meaningful representations or features from the input data. By extracting these features, foundation models can capture important patterns, structures, and characteristics of the data, which are crucial for accurate labeling.
Another important role of foundation models is prediction and classification. Once the features are extracted, foundation models utilize their learned knowledge to make predictions and assign labels to data instances.
Whether it's classifying text, detecting objects in images, or recognizing speech, foundation models can leverage their capabilities to generate annotations or labels for unlabeled data automatically.
Foundation models also excel at contextual understanding. They have the ability to comprehend the context surrounding the data, enabling them to generate accurate labels based on the provided context. This contextual understanding is particularly valuable in tasks such as natural language processing, where the meaning and interpretation of text heavily depend on the context in which it appears.
Furthermore, foundation models offer scalability and efficiency benefits. Once trained and fine-tuned, these models can rapidly process large volumes of data, reducing the need for manual labeling and saving significant time and resources.
Their scalability is particularly advantageous in big datasets or time-sensitive labeling requirements scenarios.
Key foundation models used in automated data labeling
Several key foundation models are widely used in automated data labeling. These models have been trained on large-scale datasets and exhibit remarkable capabilities in various domains. Here are some of the key foundation models used in automated data labeling:
1. GPT-3 (Generative Pre-trained Transformer 3)
GPT-3 is one of the largest language models and can be used for various data labeling tasks. It excels in generating human-like text and can be leveraged for tasks such as text classification, sentiment analysis, and content generation.
2. EfficientDet
EfficientDet is an efficient and accurate object detection model. It can quickly identify and label objects within images, making it valuable for tasks like object detection, bounding box annotation, and object recognition.
3. ALBERT (A Lite BERT)
Application in data labeling: ALBERT is a lightweight variant of BERT that offers improved efficiency without compromising performance. It can be used in various natural language processing tasks for data labeling, such as text classification, named entity recognition, and question-answering.
4. Vision Transformer (ViT)
Vision Transformer is a transformer-based model designed specifically for computer vision tasks. It can process image data and perform tasks like image classification, object detection, and semantic segmentation. ViT enables accurate and efficient labeling of visual data.
5. CLIP (Contrastive Language-Image Pre-training)
CLIP is a model that can understand text and images, allowing cross-modal data labeling. It can associate textual descriptions with visual content, enabling tasks like image captioning, cross-modal retrieval, and multimodal data labeling.
Overview of zero-shot learning and its role in automated data labeling
Zero-shot learning is a machine learning strategy that enables models to identify and categorize objects or concepts that they haven't been exposed to previously. Its significance lies in its role in automated data labeling, where unlabeled data needs to be annotated or labeled for training machine learning models.
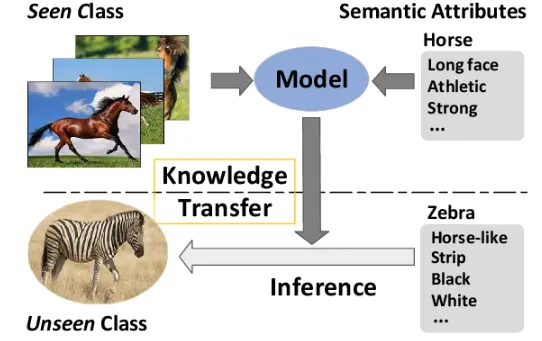
Figure: Zero-Shot Learning
The process of automated data labeling involves the following steps. Initially, a machine learning model is trained using labeled data that belongs to a subset of known classes.
Alongside this labeled data, auxiliary information is collected or provided for each class. This auxiliary information can take the form of class attributes, textual descriptions, or semantic embeddings, capturing the characteristics and relationships between classes.
The trained model then learns to map the data instances to the auxiliary information space. This mapping enables the model to associate each data point with relevant attributes or descriptions. By leveraging this learned mapping, the model can predict labels for unseen classes based on their auxiliary information.
This capability is known as zero-shot classification, as the model can classify instances into classes it has never seen during training.
With the ability to predict labels for unseen classes, the model can automatically label new, unlabeled data instances. This process of automated data labeling facilitates the generation of labeled datasets for expanding the training set or for other downstream tasks.
Zero-shot learning thus plays a crucial role in enabling automated data labeling to handle a wider range of classes without relying on extensive manual labeling efforts.
Labellerr is an example of a platform that offers automated annotation, sophisticated analytics, and intelligent quality assurance capabilities to handle vast quantities of images and extensive video content.

Figure: Labellerr, automation in Data Labelling
Definition and key concepts of zero-shot learning
Zero-shot learning is a machine learning paradigm that enables models to recognize and classify objects or concepts they have never encountered before.
Unlike traditional machine learning approaches that rely on labeled training data, zero-shot learning leverages auxiliary information or attributes associated with the classes to generalize to unseen classes.
Let's delve into some more technical concepts related to zero-shot learning:
1. Semantic Embeddings
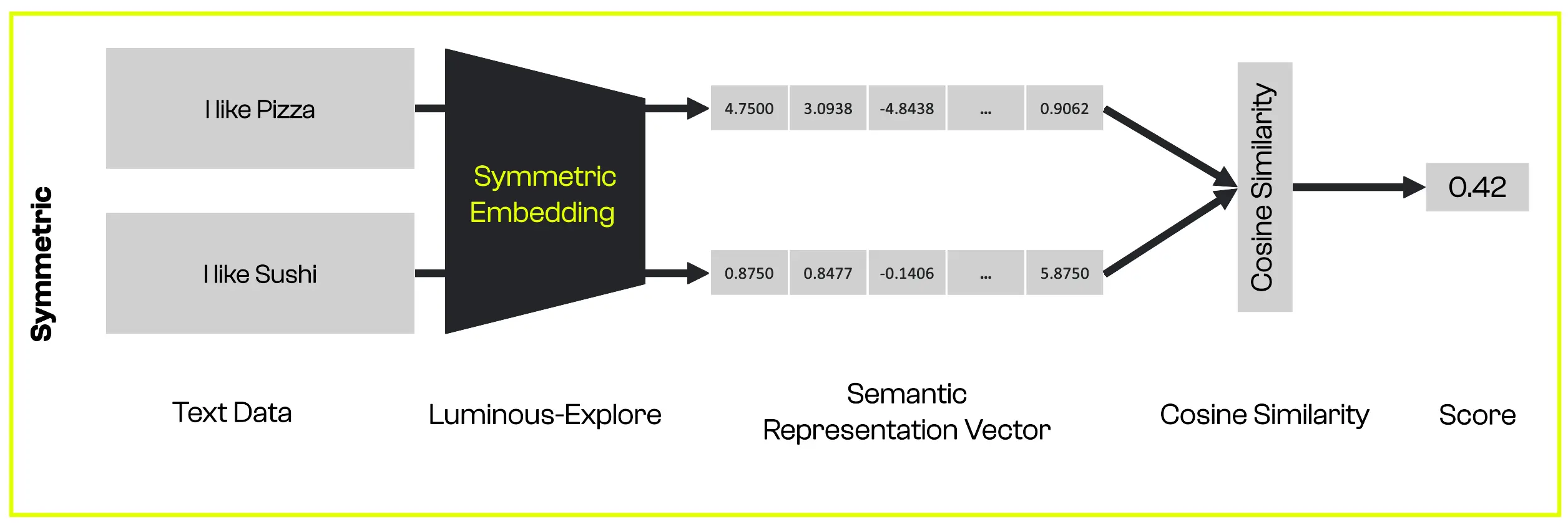
Figure: Semantic Embeddings Generation
Semantic embeddings represent data instances and class labels in a continuous vector space. These embeddings capture the semantic relationships between instances and classes. Methods like Word2Vec, GloVe, or BERT can be used to generate embeddings for textual descriptions or attributes associated with classes.
2. Attribute-based Models
In zero-shot learning, attribute-based models are commonly used. Attributes are descriptive properties associated with classes. For example, for animal classes, attributes could be "has fur," "has wings," or "lives in water." The model learns to recognize and classify instances by reasoning over these attribute vectors.
3. Compatibility Function
A compatibility function measures the similarity or compatibility between a data instance and a class in the semantic embedding space. It computes a compatibility score indicating how well the instance aligns with the attributes or descriptions of the class. This function is often used in zero-shot classification to rank and select the most suitable class label for an unseen instance.
4. Knowledge Transfer
Zero-shot learning employs knowledge transfer techniques to transfer knowledge from known classes to unseen classes. The model learns from the labeled examples of known classes and their associated auxiliary information to generalize its understanding and apply it to new, unseen classes.
5. Hybrid Models
Hybrid models combine supervised learning on known classes with unsupervised learning or generative models for unseen classes. These models aim to capture the inherent structure and distribution of data in the absence of labeled examples for unseen classes. Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) are commonly used in hybrid zero-shot learning approaches.
6. Domain Adaptation
Zero-shot learning may face challenges when there is a domain shift between the training data and the unseen classes. Domain adaptation techniques help in adapting the model to new domains by aligning the distributions of the known and unseen classes.
7. Evaluation Metrics
Standard evaluation metrics for zero-shot learning include top-1 accuracy, top-k accuracy, or the harmonic mean of precision and recall. Since zero-shot learning involves unseen classes, it is important to evaluate the model's performance on both seen and unseen classes to assess its generalization capabilities.
Challenges and limitations of traditional supervised learning and How zero-shot learning addresses these challenges
One of the significant challenges in traditional supervised learning is the limited availability of labeled data. Annotating large amounts of data can be time-consuming, expensive, and sometimes unfeasible.
This limitation hinders the scalability and applicability of supervised learning models. In contrast, zero-shot learning tackles this challenge by leveraging auxiliary information or attributes associated with classes. Instead of relying solely on labeled data, zero-shot learning utilizes the provided auxiliary information to generalize to unseen classes.
By learning the relationships and characteristics encoded in the auxiliary information, zero-shot learning models can make predictions for unseen classes without requiring explicitly labeled examples. This reduces the dependence on large labeled datasets and allows for the inclusion of a broader range of classes in the learning process.
Another challenge of traditional supervised learning in data annotation is the cost and effort required for manual labeling. Manually annotating each data point in a large dataset can be labor-intensive and expensive, particularly as the dataset size grows.
Zero-shot learning addresses this challenge by automating the data annotation process. By leveraging the auxiliary information and the learned mappings between instances and classes, zero-shot learning models can automatically assign labels or annotations to unlabeled data instances.
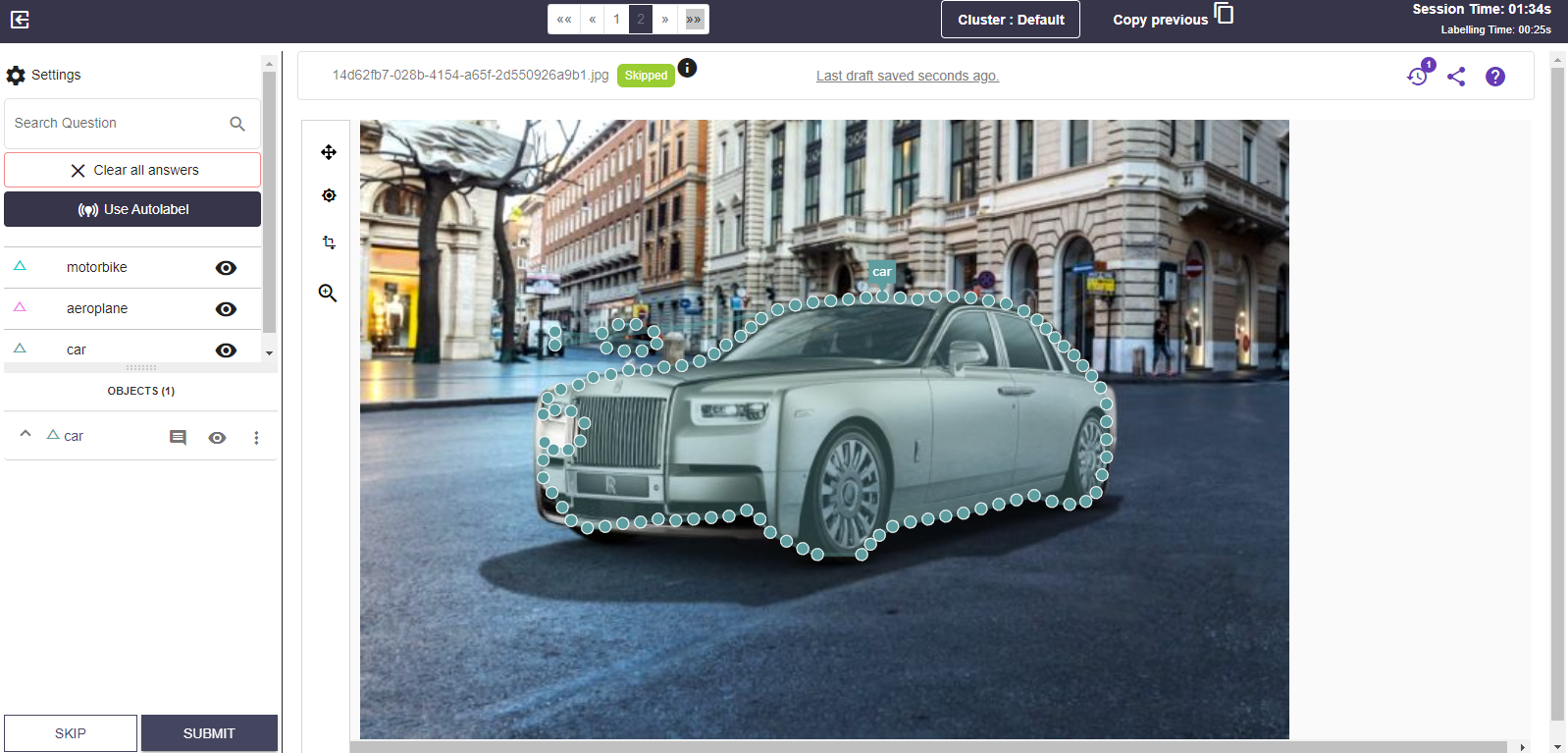
Figure: Data Annotation by labellerr
This automation significantly reduces the need for manual annotation, saving costs and time in the data labeling process. Automated data annotation facilitated by zero-shot learning enables the rapid generation of labeled datasets, making it feasible to handle large-scale datasets with minimal human effort.
Furthermore, traditional supervised learning can suffer from class imbalance, where some classes have significantly fewer examples compared to others. This class imbalance can lead to biased and inaccurate models, as the minority classes may receive less attention during training.
Zero-shot learning helps mitigate this challenge by utilizing auxiliary information that captures the characteristics of all classes, regardless of their representation in the training data. By leveraging the auxiliary information, the zero-shot learning model can reason about and make predictions for all classes, including the ones with limited labeled examples.
This capability allows for more balanced learning and accurate predictions for both majority and minority classes, even in the absence of abundant labeled data.
Zero-shot learning approaches, such as attribute-based, semantic embedding, or generative models
Zero-shot learning encompasses various approaches that enable models to recognize and classify unseen classes. Three common types of zero-shot learning approaches include attribute-based, semantic embedding, and generative models.
Attribute-based models leverage class attributes, which are descriptive properties associated with classes, to recognize and classify instances. These attributes capture high-level semantic information that distinguishes classes.
By reasoning over attribute vectors, the model learns to identify the presence or absence of certain attributes in instances, enabling zero-shot classification. Compatibility functions are often employed to measure the similarity between instance features and class attributes, facilitating accurate predictions.
Semantic embedding models focus on learning continuous vector representations that capture the relationships and similarities between instances and classes. These models aim to map instances and class labels into a shared semantic embedding space.
The model determines the compatibility between instances and classes by measuring distances or similarities in this space. Semantic embedding techniques, such as Word2Vec, GloVe, or BERT, generate embeddings for textual descriptions or attributes associated with classes. This approach enables zero-shot learning by leveraging the shared embedding space to predict labels for unseen classes.
Generative models, such as Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs), are employed in zero-shot learning to generate synthetic examples for unseen classes. These models learn the underlying data distribution from known classes and then generate new instances that resemble the unseen classes.

Figure: Generative Adversarial Networks (GANs)
Generative models bridge the gap between known and unseen classes by capturing the latent representations and generating data that aligns with the unseen class attributes or descriptions. This approach expands the available training data to include unseen classes, facilitating zero-shot classification.
Application of zero-shot learning techniques in automated data labeling
Zero-shot learning techniques find practical applications in automated data labeling across various domains. Here are a few examples of how zero-shot learning techniques are applied in automated data labeling:
1. Image Classification
Zero-shot learning can automatically label images with unseen classes in image classification tasks.
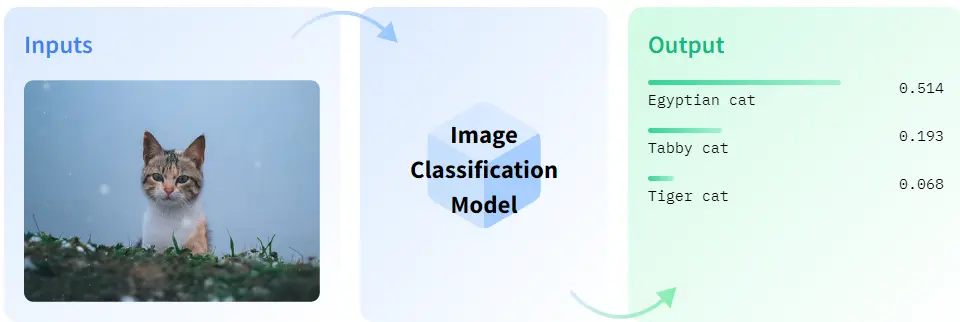
Figure: Image Classification
For example, a zero-shot learning model trained on a dataset of animal images with associated class attributes can automatically label images of new or rare animal species. By leveraging the auxiliary information about the unseen classes, such as their attributes or textual descriptions, the model can predict the appropriate labels for these images without requiring explicit labeled examples.
2. Natural Language Processing (NLP)
In NLP tasks, zero-shot learning techniques can be used for automated text classification or sentiment analysis. By utilizing semantic embedding models, the model can assign labels to text documents based on their similarity to known class descriptions or attributes.
For instance, in a news article categorization task, the model can automatically label articles with classes that were not present in the training data by leveraging their semantic embeddings and the provided auxiliary information.
3. Product Categorization
In e-commerce settings, zero-shot learning techniques can automate the categorization of new products. A zero-shot learning model can assign appropriate labels to unseen products by utilizing attributes or textual descriptions associated with product categories. This enables efficient organization and retrieval of products without the need for manual annotation.
4. Voice Recognition
Zero-shot learning can also be applied to automated voice recognition systems. By leveraging auxiliary information about speakers, such as their gender, accent, or language, a zero-shot learning model can assign labels to previously unheard speakers.
This allows for accurate speaker identification and authentication in limited training data scenarios. In these real-world applications, zero-shot learning techniques enable automated data labeling for unseen classes or instances.
By leveraging auxiliary information, such as attributes, textual descriptions, or embeddings, the models can generalize knowledge and make accurate predictions for unlabeled data, reducing the need for manual annotation and improving the efficiency of data labeling processes.
A real-world scenario of how zero-shot learning in real-world automated data labeling scenarios
In the realm of automated data labeling, zero-shot learning techniques offer technical solutions to address the challenges of labeling unseen classes and expanding labeled datasets. Let's consider a real-life example where zero-shot learning techniques are applied in automated data labeling.
Imagine a company that operates an online marketplace for clothing. They have a vast collection of products from various brands and want to automatically label new clothing items as they are added to their inventory.
However, manually labeling each item is time-consuming and costly. This is where zero-shot learning can come into play.
To tackle this challenge, the company can utilize zero-shot learning techniques to automate the labeling process for unseen classes. They can leverage auxiliary information, such as textual descriptions or attributes, associated with clothing items and brands. For instance, they can have attributes like "color," "material," "style," or brand-specific characteristics.
During training, the company builds a zero-shot learning model that learns the relationships between clothing item features and auxiliary information.
The model learns to recognize and classify clothing items based on their attributes and descriptions. It understands that a particular brand is associated with specific attributes, such as high-quality materials or a particular style.
When a new clothing item is added to the inventory, the zero-shot learning model can automatically label it based on the learned knowledge.
By analyzing the attributes and descriptions of the item, the model predicts the appropriate brand or category label, even if it hasn't encountered that specific item or brand during training. This automated labeling process saves time and effort for the company, allowing them to categorize and organize their inventory efficiently.
Furthermore, as the company expands its inventory to include clothing items from new brands or categories, the zero-shot learning model can generalize its knowledge to label these unseen classes.
The model leverages the learned mappings between attributes and classes and the semantic relationships captured in the auxiliary information to assign accurate labels to the new items. This flexibility allows the company to handle various clothing items without relying on manually labeled data for each class.
Generative AI-powered Prompt-Based Data Labeling
Generative AI models generate initial labels or annotations by providing specific prompts, serving as a starting point for human annotators. These annotators review and refine the generated outputs, ensuring accuracy and consistency.
This approach speeds up the labeling process, improves annotation consistency, and enables scalability by leveraging AI models. However, human judgment remains crucial for finalizing high-quality labeled datasets.
At Labellerr Platform, Generative AI-powered prompt-based data labeling combines the capabilities of generative AI models with carefully crafted prompts to automate and guide the data labeling process.
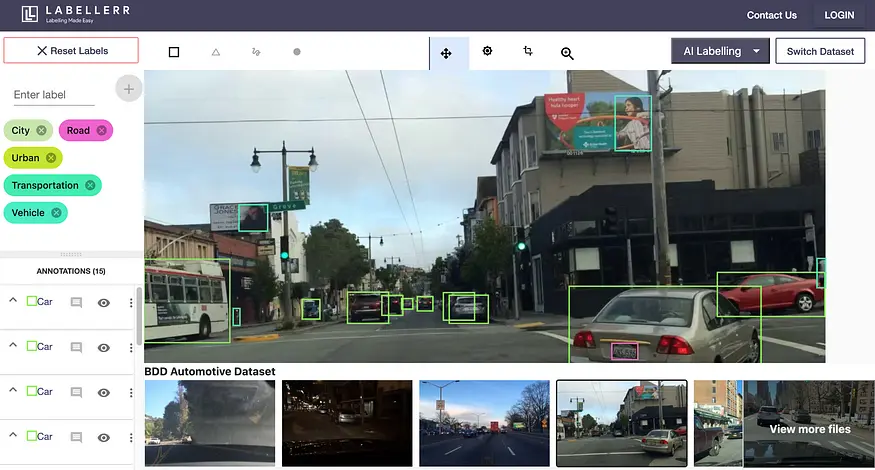
Figure: Providing Prompts for required labeled images at Labellerr
1. Prompt-Based Data Labeling
Prompt-based data labeling can also involve providing labels as prompts to guide the model in the automated labeling process. This approach leverages the inherent capability of language models to generate text conditioned on specific inputs.
In this context, the process of prompt-based data labeling with label prompts typically follows these steps:
i) Label Prompts Design
Instead of designing instructions or questions, specific label prompts are created to represent the target labels. These prompts can be in the form of statements or questions explicitly specifying the desired label.
For example, in an image classification task, label prompts may include statements like "This image belongs to the category: [label]" or questions like "What is the label for this image: [label]?"
ii) Model Execution
The label prompts, along with the unlabeled data, are provided as input to a pre-trained language model. The model generates predictions or labels based on the label prompts and its understanding of the context. By conditioning the model on the label prompts, it learns to associate the provided prompts with the corresponding labels.
iii) Post-processing
Similar to the previous approach, post-processing steps may be applied to refine the generated labels. This can involve confidence thresholding, filtering out uncertain predictions, or incorporating additional heuristics to improve the labeling quality.
iv) Iterative Refinement
As with prompt-based data labeling in general, an iterative refinement process can be applied. The initially generated labeled data can be used to fine-tune the model, and the process can be repeated with updated label prompts to improve the accuracy and reliability of the generated labels.
Using labels as prompts in the data labeling process provides flexibility and control over the generated labels. It allows for explicit specification of the desired labels, making it suitable for tasks where the label set is known and defined in advance. This approach can be applied in various domains, including text classification, image classification, sequence labeling, and more.
However, it's essential to carefully design the label prompts to ensure they are unambiguous and representative of the desired labels.
Biases present in the training data and the model's behavior can also impact the quality of the generated labels, so thorough validation and fine-tuning may be necessary to improve performance.
LabelGPT
LabelGPT, a product introduced by Labellerr is basically a software that allows all Machine Learning enthusiasts, from beginners to researchers, to generate labeled data given a collection of raw data.
Labeled data plays a crucial role in computer vision tasks as it provides the necessary ground truth information for training and evaluating machine learning models.
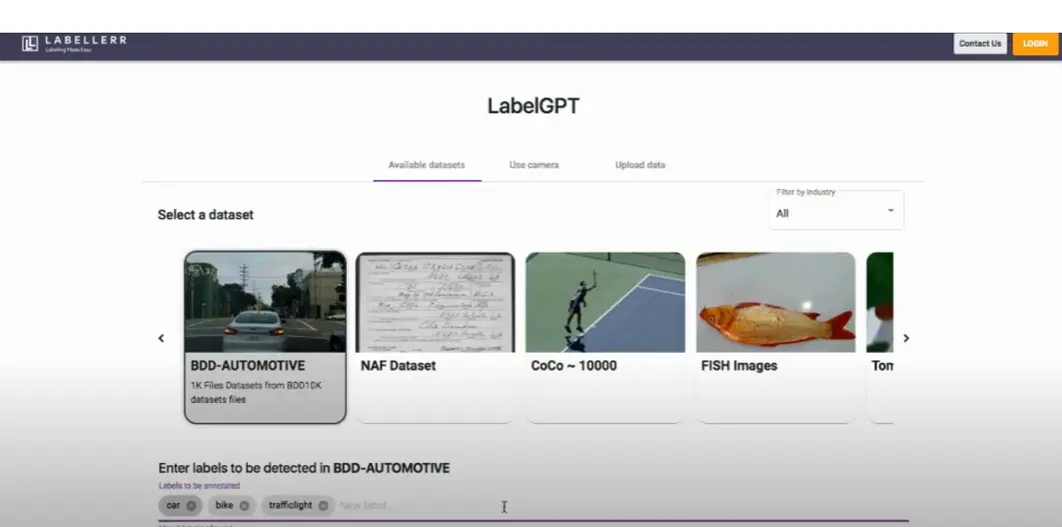
Figure: LabelGPT Interface
In computer vision, where the goal is to enable machines to understand and interpret visual information, labeled data serves as the foundation for teaching models to recognize objects, understand scenes, and perform various visual tasks.
By associating labels with images or video frames, human annotators provide annotations that indicate the presence, location, and category of objects or regions of interest within the visual data. This labeled data enables models to learn the visual patterns and features associated with different objects and allows them to generalize that knowledge to detect and classify objects in unseen data accurately.
The availability of high-quality labeled data is vital for developing and fine-tuning computer vision models, ensuring their accuracy, robustness, and generalizability in real-world applications.
LabelGPT's labeling engine leverages zero-shot labeling automation powered by foundation models. This empowers machine learning teams to produce significant quantities of labeled data efficiently. Generative AI-powered prompt-based labeling makes it super fast.
How LabelGPT Works
The data labeling process begins by importing the data into the platform. Users have the option to connect their images stored on cloud platforms such as AWS, GCP, Azure, or use local storage. The platform seamlessly integrates with these sources, enabling easy access to the images for labeling.

Figure: AWS , GCP, Azure can be directly used for importing data
Once the data is imported, users can provide a text prompt specifying the classes or objects that require labeling. They can choose between bounding box or segmentation labeling types, depending on the task at hand. The prompt acts as a guideline, ensuring consistent and accurate annotations throughout the labeling process.
After the annotations are completed, users can review the labeled images. The platform swiftly generates the labeled images along with a confidence score, indicating the reliability of the annotations. This enables users to assess the quality of the labels and make any necessary adjustments.
Finally, the labeled data can be exported and seamlessly integrated into the user's machine-learning training pipeline. This streamlined process allows for efficient data labeling and smooth integration of the labeled data into the model training workflow.
Datasets Available
Well, LabelGPT Allows one to upload and use their own dataset to get labeled data for their machine learning task. It also provides some of its own datasets, which you can try out at SandBox.
These include:
- COCO Dataset: The COCO (Common Objects in Context) dataset includes detailed annotations for object segmentation and recognition in context.It comprises a dataset of 330,000 images, out of which more than 200,000 images are annotated with labels for a total of 1.5 million object instances.
- Halloween Costumes Dataset: This Dataset contains images of people dressed in costumes of various superheroes.
- Tomato Dataset: This dataset contains images of tomatoes with different orientations.
- BDD Automotive Dataset: This Dataset contains images of vehicles on the road, mainly cars, and is used for vehicle detection.
- Taco Dataset: The taco dataset is a publicly available collection of images that focuses on waste found in natural and urban environments. It comprises photographs depicting litter in various settings, ranging from tropical beaches to the bustling streets of London.

Figure: COCO Dataset
Benefits of LabelGPT
The benefits of using the labeling engine are significant. Firstly, it eliminates the need for manual labeling, as users can provide the class/object name and rely on the foundation model-powered engine to automatically detect and segment the labels. This zero-shot labeling approach saves valuable time and effort.
Another advantage is the speed at which labels can be generated. With a single click, users can run the model on their entire dataset and obtain labeled data within minutes. This eliminates the need for laboriously labeling images one by one, allowing for rapid processing of large volumes of data.
The review process is made easy and efficient. Users can filter the labeled data based on high confidence scores, enabling them to validate the quality of the labels quickly. This visual validation step ensures the accuracy and reliability of the generated labels before pushing them to their machine-learning pipeline for further utilization.
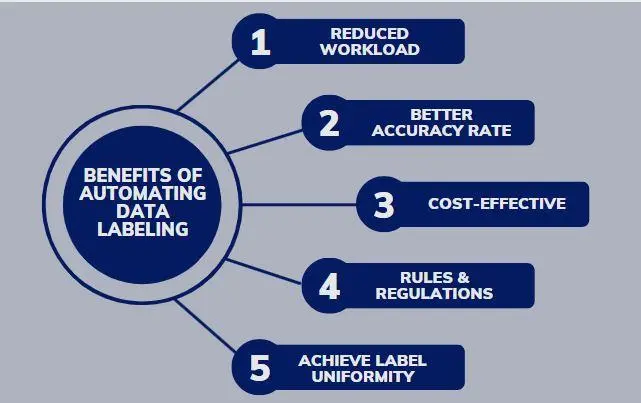
Figure: Benifits of Automating Data-labelling
Labellerr offers an AI-powered data annotation platform that leverages foundation models and prompt engineering to streamline your data labeling process. Request a demo today.
Conclusion
In conclusion, data labeling is a critical step in training machine learning and AI models, involving the annotation or tagging of data samples to provide meaningful information for algorithm training.
Manual data labeling by human annotators and automated techniques using pre-defined rules or algorithms are the two main approaches. Automating the data labeling process brings benefits such as improved efficiency, cost-effectiveness, consistency, scalability, reproducibility, and the ability to improve labeling accuracy iteratively.
Understanding prerequisite concepts like supervised learning, unsupervised learning, semi-supervised learning, reinforcement learning, and self-supervised learning is crucial for comprehending and implementing automated data labeling techniques.
About zero-shot learning is a powerful technique that enables models to recognize and classify unseen classes or instances by leveraging auxiliary information. It plays a crucial role in automated data labeling by reducing the dependence on extensive manual annotation and allowing for the inclusion of a broader range of classes in the learning process.
Zero-shot learning approaches, such as attribute-based, semantic embedding, and generative models, provide effective solutions to overcome the challenges of limited labeled data, manual labeling effort, and class imbalance.
By automating the data labeling process, zero-shot learning facilitates the rapid generation of labeled datasets, improving scalability and efficiency in various domains such as image classification, natural language processing, product categorization, and voice recognition.
Finally, we learned about LabelGPT offers a powerful solution for generative AI-powered prompt-based data labeling, revolutionizing the data labeling process across various industries and machine learning tasks.
By combining the capabilities of generative AI models with carefully designed prompts, LabelGPT automates and guides the data labeling process, improving efficiency, annotation consistency, and scalability.
The platform's ability to generate accurate labels based on text prompts eliminates the need for manual labeling, saving time and effort. Additionally, LabelGPT enables rapid processing of large volumes of data, with labels generated within minutes. The review process is made efficient with the ability to filter and validate labeled data based on confidence scores.
Overall, LabelGPT streamlines the data labeling workflow, providing high-quality labeled data for training and evaluating machine learning models and accelerating the development and deployment of computer vision applications.
Frequently Asked Questions (FAQ)
1. What is the difference between self-supervised and unsupervised learning?
Self-supervised learning and unsupervised learning are both types of machine learning techniques that aim to extract meaningful patterns and representations from data. However, there are subtle differences between these two approaches.
i) Unsupervised Learning
Unsupervised learning is a branch of machine learning where the goal is to learn patterns and structures in data without explicit labels or annotations.
It involves finding inherent structures, relationships, or similarities within the data itself. In unsupervised learning, the algorithm is left to discover the underlying patterns and dependencies on its own without any specific guidance.
The main objectives of unsupervised learning are:
- Clustering: Grouping similar data points together based on their intrinsic properties. Clustering algorithms aim to identify natural clusters or subgroups within the data.
- Dimensionality Reduction: Reducing the number of features or variables in the data while preserving the essential information. Dimensionality reduction techniques aim to capture the most relevant and informative aspects of the data in a lower-dimensional space.
- Anomaly Detection: Identifying unusual or abnormal instances in the data that deviate significantly from the expected patterns.
- Density Estimation: Modeling the probability distribution of the data, which can be useful for understanding the data generation process or detecting outliers.
ii) Self-Supervised Learning
Self-supervised learning is a specific type of unsupervised learning that leverages the inherent structure or information present in the data itself as a source of supervision.
In self-supervised learning, the data is transformed in a way that creates a surrogate supervisory signal, allowing the model to learn meaningful representations.
The key idea in self-supervised learning is to design a pretext task or a surrogate supervised task based on the data itself without relying on external labels. The model is trained to solve this pretext task, which involves predicting or reconstructing certain parts of the input data.
By learning to perform this pretext task successfully, the model implicitly learns useful representations that capture the underlying structure of the data.
Self-supervised learning is particularly useful when labeled data is scarce or expensive to obtain.
By leveraging the abundance of unlabeled data and designing pretext tasks, self-supervised learning enables models to learn rich representations without relying on explicit labels. Examples of self-supervised learning methods include contrastive learning, predictive coding, and autoencoders.
2. What is the difference between Zero-shot Learning and unsupervised learning?
The difference between unsupervised learning and zero-shot learning is that:
i) In Unsupervised Learning
- Objective: Discover patterns, relationships, or structures in data without using labeled examples.
- Methodology: Focuses on finding intrinsic patterns or representations within the data itself.
- Labeled Data: Unsupervised learning does not require labeled data for training.
- Tasks: Common tasks include clustering, dimensionality reduction, and anomaly detection.
- Learning Process: Relies solely on the inherent structure of the data to learn and uncover hidden patterns.
ii. In Zero-Shot Learning
- Objective: Classify or recognize objects or concepts for which no labeled examples are available during training.
- Methodology: Leverages auxiliary information or prior knowledge to generalize knowledge to unseen classes.
- Labeled Data: Zero-shot learning typically requires labeled data for some seen classes but not for all classes.
- Tasks: The focus is on accurately classifying unseen classes based on the learned associations with auxiliary information.
- Learning Process: Involves learning the associations between classes and auxiliary information to make predictions for unseen classes.
3. Why do we need to automate the data labeling process?
Automating the data labeling process brings several advantages and is essential in data-driven applications.
One of the key benefits is improved efficiency. Manual data labeling can be time-consuming, especially with large datasets. Automation allows for faster and more scalable labeling, reducing the time and resources needed to process extensive amounts of data.
In addition to efficiency, automating data labeling is cost-effective. Hiring and training human annotators can be expensive.
Automation reduces costs by minimizing the reliance on manual labor, enabling organizations to label data at a lower cost. These saved resources can then be allocated to other important areas.
Consistency is another crucial aspect. Human annotators may introduce inconsistencies and biases when labeling data, leading to errors and variations in the labeled dataset. Automation ensures a consistent approach to data labeling, reducing the risk of human errors and maintaining a higher quality of labeled data.
The scalability of automated data labeling is significant as datasets continue to grow in size. Manual labeling becomes increasingly challenging and time-consuming. Automation enables organizations to handle larger datasets while maintaining quality and requiring a significant increase in resources.
Automated data labeling also facilitates reproducibility. The same labeling algorithm or rules can be consistently applied to new data, ensuring that results can be reliably compared and reproduced. This promotes experimentation and evaluation of machine learning models.
Moreover, automated processes can be iteratively improved. Labeling accuracy can be continuously enhanced by refining the labeling algorithms or rules based on feedback and new data. This adaptability is crucial in dynamic environments where requirements may change over time.
By automating data labeling, domain experts can focus on higher-level tasks that require their expertise. This allows them to contribute strategically to the project by refining labeling rules or analyzing the labeled data. Automation frees up their time, enabling more effective utilization of domain knowledge.
4. What is the difference between Self-supervised and Semi-supervised learning?
Self-supervised learning and semi-supervised learning are two different approaches to machine learning, particularly in the context of training models with limited labeled data. Here's an overview of the differences between self-supervised learning and semi-supervised learning:
i) Self-supervised Learning
Self-supervised learning is a type of unsupervised learning where a model learns to predict certain aspects of the data without explicit human annotations. The idea is to design a pretext or auxiliary task that provides supervision signals within the data itself. The model is trained on unlabeled data by creating surrogate labeling tasks.
ii) Semi-supervised Learning
Semi-supervised learning, on the other hand, is a learning paradigm that utilizes both labeled and unlabeled data for training. In this approach, a small portion of the data is labeled, while the majority remains unlabeled. The goal is to leverage the unlabeled data to improve the model's performance and generalization capabilities.
5. What is zero-shot learning and how does it facilitate automated data labeling?
Zero-shot learning is an approach in machine learning that allows models to identify and categorize objects or concepts that they have not previously encountered. Its significance lies in its role in automated data labeling, where unlabeled data needs to be annotated or labeled for training machine learning models.
The process involves training a model using labeled data for a subset of known classes and collecting auxiliary information for each class. This auxiliary information, such as attributes or textual descriptions, captures the characteristics and relationships between classes.
The model then learns to map data instances to the auxiliary information space, enabling it to associate each data point with relevant attributes or descriptions. By leveraging this mapping, the model can predict labels for unseen classes based on their auxiliary information.
This capability, known as zero-shot classification, allows for the automatic labeling of new, unlabeled data instances, facilitating the generation of labeled datasets without extensive manual labeling efforts.
6. What is zero-shot learning?
Zero-shot learning (ZSL) is a problem setup in machine learning in which the model is asked to solve a prediction task that it was not trained on. This typically entails the ability to identify or categorize data into concepts that the model has not been directly exposed to during its training phase.
7. What is zero data learning?
This often involves recognizing or classifying data into concepts it had not explicitly seen during training.
8. What is a foundation model in AI?
A foundation model (also called base model) is a large machine learning (ML) model trained on a vast quantity of data at scale (often by self-supervised learning or semi-supervised learning) such that it can be adapted to a wide range of downstream tasks.
9. How does generative AI-powered prompt-based data labeling ensure the accuracy and reliability of generated labels?
Generative AI-powered prompt-based data labeling combines the capabilities of generative AI models with carefully crafted prompts to automate and guide the data labeling process.
While the AI model generates initial labels based on the provided prompts, human annotators play a crucial role in reviewing and refining the generated outputs. This human-in-the-loop approach ensures that the final labeled datasets are accurate and consistent. Human judgment and expertise are essential for validating and improving the quality of the generated labels, maintaining high standards of accuracy and reliability.
10. Can generative AI-powered prompt-based data labeling be applied to different domains and tasks?
Yes, generative AI-powered prompt-based data labeling can be applied to various domains and tasks, including text classification, image classification, sequence labeling, and more.
The approach allows for flexibility and control over the generated labels by designing specific label prompts that represent the desired labels. It is particularly suitable for tasks where the label set is known and defined in advance. By conditioning the AI model on the label prompts, it learns to associate the provided prompts with the corresponding labels, enabling accurate and context-aware labeling.
However, it is important to carefully design the label prompts to ensure they are unambiguous and representative of the desired labels, and iterative refinement may be necessary to improve the labeling performance based on domain-specific requirements.
11. What is the difference between reinforcement learning and self-supervised learning?
Reinforcement Learning and Self-Supervised Learning are two distinct approaches to machine learning, each with its own characteristics and objectives. Here's a comparison of the two:
i) Reinforcement Learning
Reinforcement Learning (RL) is a type of machine learning where an agent learns to make decisions and take actions in an environment to maximize a cumulative reward signal.
RL involves an agent interacting with an environment, learning through trial and error, and receiving feedback in the form of rewards or punishments based on its actions.
Key Points:
- Objective: The goal of RL is to learn an optimal policy that maximizes the expected cumulative reward over time.
- Agent-Environment Interaction: RL agents interact with an environment, observing its state, taking actions, and receiving rewards based on their actions.
- Feedback: The agent learns from the feedback in the form of rewards or penalties received after each action.
- Exploration and Exploitation: RL involves a trade-off between exploration (trying out new actions to gather more information) and exploitation (taking actions that are known to have higher rewards).
- Sequential Decision-Making: RL focuses on learning a policy that determines the agent's actions based on the current state and future expected rewards.
Applications: RL is commonly used in scenarios such as game playing, robotics, recommendation systems, and autonomous driving.
ii) Self-Supervised Learning
Self-Supervised Learning is a type of unsupervised learning where a model learns to make predictions or generate labels from unlabeled data using the inherent structure or information present in the data itself. The data is transformed in a way that creates a surrogate supervisory signal, allowing the model to learn meaningful representations.
Key Points:
- Objective: The goal of self-supervised learning is to learn useful representations from unlabeled data without relying on explicit labels.
- Surrogate Tasks: Instead of using labeled data, self-supervised learning designs surrogate tasks (e.g., predicting missing parts, context prediction, etc.) that create a pretext for the model to learn meaningful representations.
- Unlabeled Data: Self-supervised learning leverages abundant unlabeled data to learn representations, making it particularly useful in scenarios where labeled data is scarce or expensive to obtain.
- Transfer Learning: Self-supervised learning focuses on learning representations that can be transferred to downstream tasks, where labeled data might be limited.
Applications: Self-supervised learning has been successfully applied in computer vision tasks like image representation learning, video understanding, and pre-training models for transfer learning.
12. What is automated data labeling?
Automated Data Labeling is a groundbreaking procedure that has revolutionized the data processing and analysis capabilities of businesses. Thanks to advancements in machine learning algorithms, it is now feasible to automatically assign labels or tags to large volumes of data in a streamlined manner.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
