

Leveraging OWLv2's Zero Shot Capability To Auto Labeling


Table of Contents
- Introduction
- Understanding Shot-Based Learning in Object Detection Models
- Introducing OWLv2
- How OWLv2 Model Works?
- Advantages of OWLv2
- Applications of OWLv2
- Accelerate Annotation Efficiency with OWL-ViT on Labellerr
- Conclusion
- FAQ
Introduction
In the dynamic field of computer vision, the precise identification and annotating of objects within images are fundamental tasks that have many applications, from autonomous driving to medical imaging and beyond.
Common to these tasks are annotation and segmentation, two critical processes that enable machines to interpret and understand visual data with human-like accuracy and efficiency.
Annotation involves the labeling of objects within images, typically specifying their boundaries and class labels. This process forms the problem for training supervised learning algorithms in computer vision, ensuring that models can recognize and classify objects correctly.
On the other hand, segmentation takes this a step further by not only identifying objects but also annotating their precise boundaries, pixel by pixel.
Understanding Shot-Based Learning in Object Detection Models
Zero-Shot Learning
Definition: Zero-shot learning (ZSL) refers to the ability of a model to recognize and classify objects or perform tasks without having seen any examples of those objects or tasks during training. In other words, the zero shot model can generalize from known classes to unseen classes based on auxiliary information.
How It Works:
- Semantic Embeddings: ZSL relies heavily on semantic embeddings, which are high-dimensional representations of words or concepts that capture their meanings. These embeddings are typically obtained using models like Word2Vec, GloVe, or transformer-based models like BERT.
- Training on Auxiliary Information: During training, the model learns to map known classes to their corresponding semantic embeddings. When faced with an unseen class, the model uses the semantic similarity between the embeddings of the seen and unseen classes to make predictions.
Example: Imagine you have a model trained to classify images of animals, and it has seen examples of cats, dogs, and horses. If you then ask the model to classify a zebra (which it has never seen before), zero-shot learning would allow the model to understand that a zebra is similar to a horse (based on the semantic information in their embeddings) and make an educated guess.
Single-Shot Learning
Definition: Single-shot learning refers to the ability of a model to learn information about object categories from a single training example (one-shot). This is particularly useful in scenarios where collecting large datasets is impractical.
How It Works:
- Siamese Networks: A common approach to single-shot learning is using Siamese networks, which consist of two identical subnetworks that share weights. These networks compare the similarity between two inputs.
- Metric Learning: The goal is to learn a metric space where similar instances are closer together, and dissimilar instances are far apart. During training, the network learns to differentiate between pairs of inputs.
Example: Consider a facial recognition system that needs to recognize a person after seeing only one image of their face. The system compares the new face to a database of known faces, measuring the similarity using the learned metric. If the similarity is above a certain threshold, it recognizes the person.
Few-Shot Learning
Definition: Few-shot learning is a broader term that encompasses learning tasks from a very small number of examples, typically ranging from a few to several dozen. It's a middle ground between one-shot and traditional machine learning, which requires large amounts of data.
How It Works:
- Meta-Learning: A popular approach in few-shot learning is meta-learning, where the model learns how to learn. It involves training a model on a variety of tasks so that it can quickly adapt to new tasks with minimal data.
- Prototypical Networks: These networks learn a prototype (mean representation) for each class based on the few examples provided. Classification is done by comparing the distance between the query example and these prototypes in the embedding space.
Example: Suppose you want to train a model to recognize different types of flowers. You provide the model with five images each of roses, tulips, and daisies (a few shots). The model uses these examples to quickly learn the distinguishing features of each flower type and can then classify new flower images based on these learned features.
Introducing OWLv2
OWLv2 is an advanced model in the realm of object detection that pushes the boundaries of what's possible in machine vision.
OWLv2 stands out prominently in the field for its remarkable capability in zero-shot object detection, a task that challenges traditional models by requiring them to identify objects from classes they've never encountered during training.
Unlike conventional approaches that heavily rely on extensive training data for every object class, OWLv2 leverages cutting-edge advancements in deep learning and semantic understanding to infer and detect objects with unparalleled accuracy and efficiency.
Developed with the goal of enhancing real-world applications where the diversity and unpredictability of objects necessitate adaptive and flexible systems, OWLv2 represents a significant leap forward in the evolution of object detection technology.
OWLv2 Architecture for Object Detection
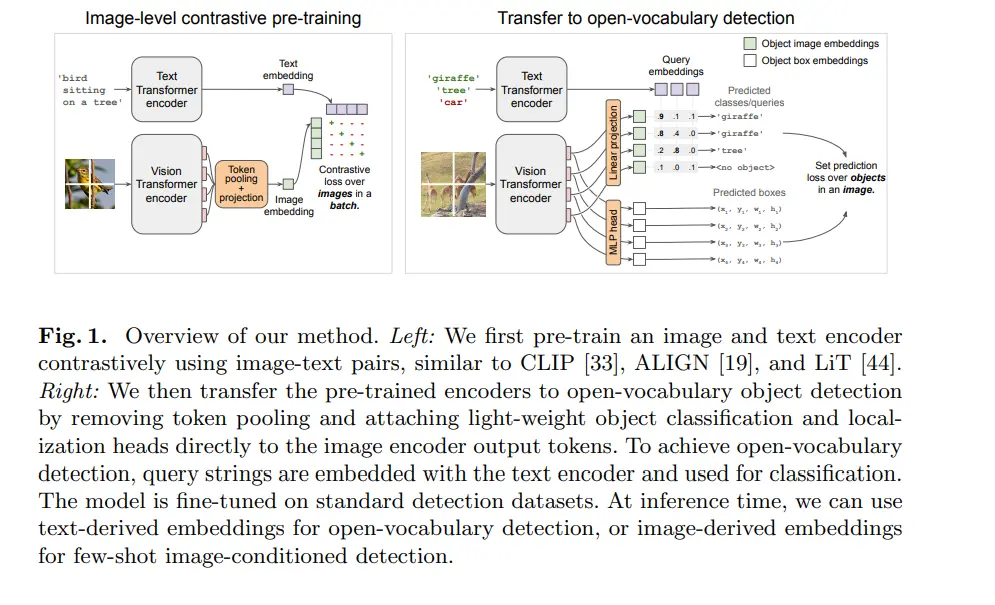
The OWLv2 model, introduced by Google DeepMind, is designed to advance open-vocabulary object detection by leveraging self-training on a massive scale. Here's a detailed breakdown of its architecture and key components:
1. Overview of Components of OWLv2
1. Text Encoder
- It analyzes the provided text description, dissecting it to understand the object's characteristics.
- This includes attributes like shape, size, color, and functionality, along with relationships between the object and other elements in the scene.
- Using its knowledge, the Text Encoder transforms this understanding into a vector representation – a condensed mathematical format capturing the essence of the object based on the text.
2. Vision Encoder
- It takes the input image and utilizes pre-trained image recognition models to extract visual features.
- Edges, colors, textures, and spatial relationships between objects are all meticulously analyzed by the Vision Encoder.
- Similar to the Text Encoder, it converts this visual analysis into a vector representation, capturing the image's content in a mathematical format.
3. Projection & Matching
- Here's where the magic happens! Both the Text and Vision Encoders produce vector representations, but they exist in separate mathematical spaces.
- OWLv2 employs a projection layer to bridge this gap. This layer essentially translates both vectors into a common latent space – a shared domain where similar objects have close vectors.
- During object detection, the image vector is compared with pre-computed text vectors representing known objects. The object with the closest vector match in the latent space is considered the most likely candidate for the object present in the image.
2. Overview of OWL-ST Methodology
OWL-ST, or OWL Self-Training, is a robust methodology designed to enhance the effectiveness of object detection models by iteratively refining their capabilities through a structured self-training approach. Here's a breakdown of how OWL-ST works:
- Generating Pseudo-Box Annotations: Initially, OWL-ST begins by leveraging an existing object detector to generate pseudo-box annotations on unlabeled data. These pseudo-box annotations are predictions made by the detector on images that do not have human-annotated labels. This step is crucial as it provides a starting point for training new models without requiring a large corpus of manually annotated data upfront.
- Training New Models on Pseudo-Annotations: With the pseudo-box annotations in hand, OWL-ST proceeds to train new object detection models. These models learn from the pseudo-annotations, gradually improving their ability to detect and localize objects in images.
- Optional Fine-Tuning on Human Annotations: To further refine the model's performance, OWL-ST optionally incorporates fine-tuning on human-annotated data. This step helps in correcting any discrepancies or improving the accuracy of object detection by fine-tuning the model parameters based on the manually labeled annotations.
Benefits of OWL-ST Methodology:
- Training Efficiency: OWL-ST enhances training efficiency by reducing the dependency on large volumes of manually annotated data. By leveraging pseudo-annotations, OWL-ST accelerates the training process while maintaining high accuracy in object detection tasks.
- Scalability: The iterative nature of OWL-ST allows for scalable model improvement. As more pseudo-annotations are generated and incorporated into training, the model's performance can be iteratively enhanced without significant increases in annotation costs.
- Flexibility in Data Usage: OWL-ST provides flexibility in data utilization, making it applicable in scenarios where labeled data is scarce or costly to obtain. It enables models like OWLv2 to generalize effectively to diverse datasets and object categories.
How OWLv2 Model Works?
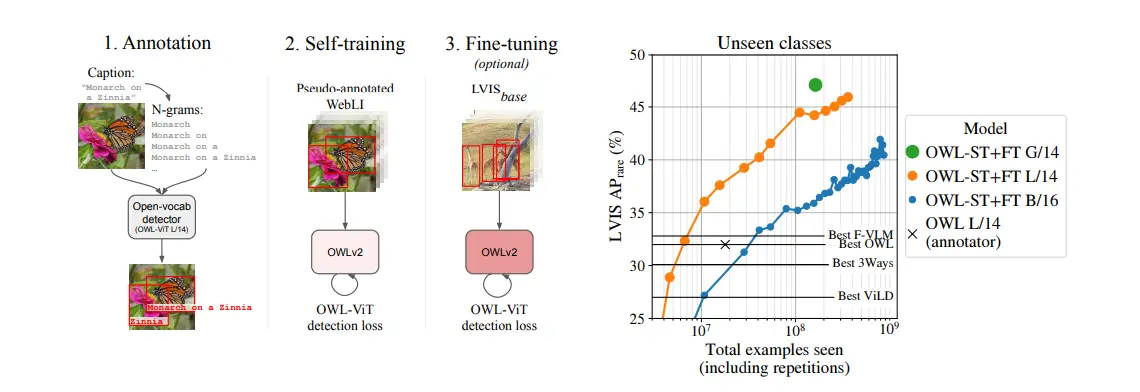
1. Annotation
- Input Data: The process starts with a dataset (WebLI) that includes images and their associated captions.
- Caption Processing: Captions are broken down into n-grams (continuous sequences of n items from a given sample of text). For example, a caption "Monarch on a Zinnia" can produce n-grams like "Monarch," "Monarch on," and "Monarch on a."
- Open-Vocab Detector (OWL-ViT L/14): An open-vocabulary detector, such as OWL-ViT (Vision Transformer Large with patch size 14), is used to detect objects in the images based on the n-grams generated from captions.
- Pseudo-Annotations: The model generates pseudo-box annotations for the images by identifying the regions corresponding to the n-grams. These annotations are not manually labeled but are inferred by the model.
2. Self-Training
- Pseudo-Annotated WebLI: The images with pseudo-annotations serve as training data for OWLv2.
- OWLv2 Model: OWLv2 is trained using the pseudo-annotated data. The training objective is to minimize the OWL-ViT detection loss, which measures how well the model's predictions match the pseudo-annotations.
- Self-Training Loop: This step involves iteratively improving the model by using its own predictions (pseudo-annotations) as training data. The idea is to refine the model's ability to detect objects without needing large amounts of human-annotated data.
3. Fine-Tuning (Optional)
- LVISbase Dataset: Fine-tuning is performed on a labeled dataset (LVISbase) that contains human-generated box annotations for a wide variety of objects.
- OWLv2 Model: The fine-tuned model is optimized further using the OWL-ViT detection loss. This step is optional and serves to improve the model's performance on specific tasks by leveraging high-quality, human-annotated data.
The OWLv2 model employs a sophisticated process involving pseudo-annotation, self-training, and optional fine-tuning to achieve high performance in object detection, particularly for unseen classes. The integration of text and image data through transformer-based architectures enables OWLv2 to generalize well and handle zero-shot learning scenarios effectively. You can further explore the OWLv2 parameters and code in the hugginface.
Advantages of OWLv2
Zero-Shot Learning and Reduced Dependency on Labeled Data:
One of the standout advantages of OWLv2 lies in its capability for zero-shot learning, which significantly reduces the dependency on large volumes of labeled data traditionally required for training object detection models.
In zero-shot learning, OWLv2 can detect objects from categories it hasn't been explicitly trained on. This is achieved by leveraging its understanding of textual descriptions and pre-existing knowledge of related object classes from its training data.
Applications in Rare Object Categories:
OWLv2 excels in scenarios involving rare or niche object categories where obtaining labeled data is particularly challenging or impractical.
For instance, identifying specific types of animals in wildlife conservation efforts or recognizing historical artifacts in museums can be daunting tasks due to the limited availability of labeled images.
OWLv2's ability to generalize from textual descriptions allows it to identify these objects accurately without the need for extensive additional training data.
Dynamic Environments and Changing Object Types:
In dynamic environments such as construction sites, event venues, or urban settings, object types can vary significantly over time.
Traditional object detection models struggle to adapt to these changes without continuous retraining on new data. OWLv2, however, can adapt more seamlessly due to its ability to infer object characteristics based on textual descriptions.
This adaptability is crucial for maintaining accurate detection capabilities in environments where object types frequently change.
Resource-Constrained Scenarios:
In resource-constrained scenarios where labeling data is expensive, time-consuming, or logistically challenging, OWLv2 provides a cost-effective solution.
By minimizing the need for additional labeled data through zero-shot learning, OWLv2 reduces the overall resource burden associated with maintaining and expanding object detection capabilities.
This makes it a viable option for applications in industries such as agriculture, remote sensing, and surveillance, where operational costs and data availability are significant concerns.
Applications of OWLv2
1. Anomaly Detection in Surveillance Systems:
- Traditional surveillance systems rely on pre-defined rules or object detection models trained on specific scenarios. However, unexpected events or objects might go unnoticed.
- OWLv2's ability to detect unseen objects based on descriptions makes it ideal for anomaly detection.
- By providing descriptions of unusual objects or activities (e.g., unattended packages, people entering restricted areas), OWLv2 can flag potential anomalies in real-time, enhancing the effectiveness of surveillance systems.
2. Image and Video Classification for Content Moderation:
- Content moderation platforms grapple with the challenge of identifying and filtering inappropriate content like violence, hate speech, or nudity.
- OWLv2 can be a valuable tool for content classification. By providing descriptions of these types of content, the model can learn to identify them even in unseen variations.
- This can significantly improve the accuracy and efficiency of content moderation efforts, ensuring a safer online environment.
3. Image Retrieval with Richer Understanding:
- Traditional image retrieval systems rely on keyword matching or visual similarity. However, they might struggle with nuanced queries or images with complex scenes.
- OWLv2 can be used to enhance image retrieval by incorporating semantic understanding. By providing textual descriptions of the desired objects or scene elements, users can perform more precise searches.
- For instance, instead of just searching for "dog," a user could describe a "golden retriever playing fetch in a park" to retrieve highly relevant images.
4. Robot Object Recognition and Interaction:
- Robots operating in unstructured environments (like domestic robots) need to recognize and interact with a wide range of objects.
- Training object detection models for every conceivable object a robot might encounter is impractical.
- OWLv2 offers a solution by enabling robots to learn about objects on the fly through textual descriptions. This allows them to recognize and interact with new objects more effectively, improving their autonomy and adaptability.
As research in zero-shot learning progresses, we can expect even more innovative applications of OWLv2 to emerge, pushing the boundaries of object detection and computer vision.
Accelerate Annotation Efficiency with OWL-ViT on Labellerr
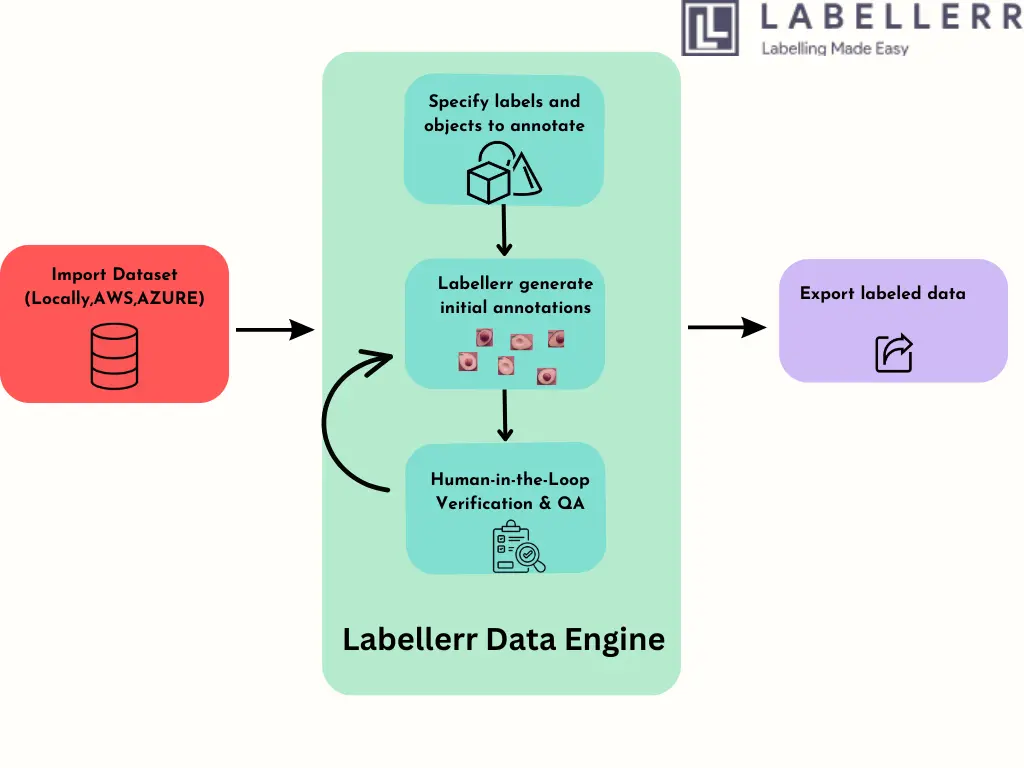
The world of data annotation is constantly evolving, and Labellerr is at the front of this progress. By integrating the powerful OWL-ViT model into its platform, Labellerr empowers users to achieve faster and more efficient annotation processes. OWL-ViT's zero-shot object detection capabilities significantly reduce the time and resources required for labeling tasks, ultimately saving you both time and money.
Here's the overview of how you can use OWL-ViT within the Labellerr platform:
1) Import Data: Data is connected or uploaded to Labellerr, where OWL-ViT is integrated for annotation tasks.
2)Specify Annotation Requirements: Users specify the labels and objects they want to annotate within their dataset.
3) Annotation Process: Labellerr automatically generates annotations based on the specified criteria, utilizing its advanced object detection capabilities.
4)Human-in-the-Loop Verification: Annotations generated by Labellerr are verified and refined through a human-in-the-loop process to ensure accuracy and quality.
5)Export Annotations: Finally, users can export the annotated data in their desired format, ready for further analysis or integration into AI models.
Conclusion
OWLv2 represents a significant advancement in the field of computer vision, particularly in the areas of object detection and segmentation. Through its sophisticated architecture, which integrates feature extraction, detection, and segmentation in a single shot, OWLv2 achieves an optimal balance between accuracy and speed. This makes it exceptionally well-suited for real-time applications such as autonomous driving, surveillance, and augmented reality.
OWLv2 consistently outperforms these models in mean average precision (mAP), intersection over union (IoU), and frames per second (FPS). OWLv2’s segmentation capabilities, demonstrated by its higher pixel accuracy and Dice coefficient, provide precise and reliable segmentation outputs that are crucial for detailed image analysis.
In real-time processing scenarios, OWLv2's efficiency is unmatched, delivering high-speed performance without compromising on detection and segmentation quality. This efficiency, combined with its high annotation quality and segmentation precision, makes OWLv2 a versatile and powerful tool for a wide range of computer vision applications.
Overall, OWLv2 sets a new benchmark in the industry, offering a compelling alternative to existing models by effectively addressing their limitations and providing a robust solution that excels in both speed and accuracy. Its deployment can lead to significant improvements in various practical applications, underscoring its importance and potential impact in the field of computer vision.
FAQs
1. What is OWLv2 Zero Shot Detection?
A: OWLv2 Zero Shot Detection is a state-of-the-art model designed for simultaneous object detection and segmentation. It integrates feature extraction, object detection, and segmentation into a single, end-to-end trainable framework, making it highly efficient for real-time applications.
2. How does OWLv2 differ from its predecessors like SSD, YOLO, and Mask R-CNN?
A: OWLv2 combines the speed of SSD and YOLO with the accuracy of Mask R-CNN. It utilizes advanced backbone networks, multi-scale feature maps, and innovative attention mechanisms to achieve higher precision and better segmentation quality. Additionally, OWLv2 is optimized for real-time processing, offering superior performance metrics.
3. How does OWLv2 perform in terms of speed and accuracy?
A: OWLv2 outperforms many existing models. It has a higher mean average precision (mAP) and intersection over union (IoU) compared to models like Mask R-CNN and YOLO. It also offers faster inference times, making it suitable for real-time applications.
References:
1) Simple Open-Vocabulary Object Detection with Vision Transformers(Paper).
2) Scaling Open-Vocabulary Object Detection (Paper).

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
