

Active Learning: Less Data, Smarter Models

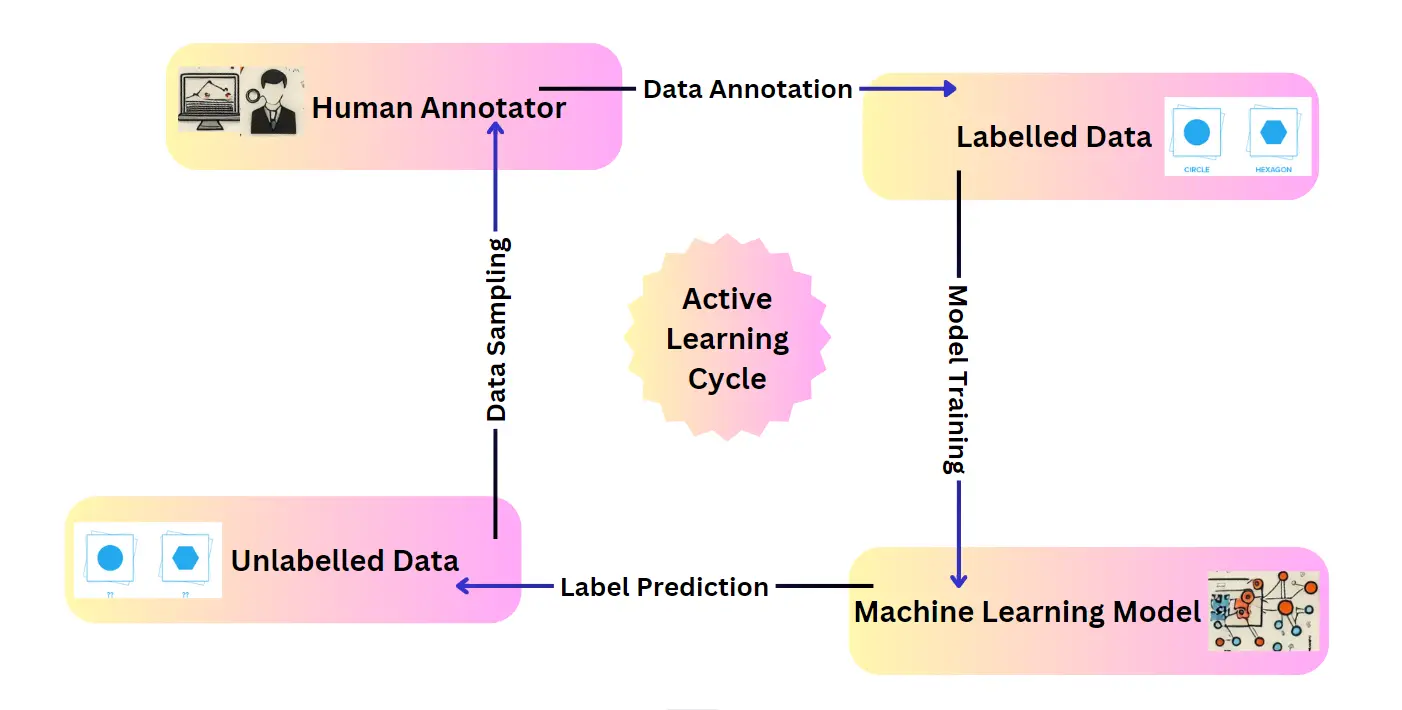
Active learning is a paradigm shift in the traditional supervised learning approach. Unlike passive learning, which relies on a pre-defined, static set of labeled data for training, active learning algorithms actively participate in the data selection process.
This blog delves into the core concepts of active learning and its key differences from passive learning.
In this blog, we'll cover the mentioned topics:
Table of Contents
- Introduction
- Why use active learning?
- How does active learning work?
- Active Learning Query Selection Strategies
- Challenges of active learning
- Applications of Active Learning
- Conclusion
- FAQ
- References
Introduction
Active Learning: Selective Sampling for Enhanced Learning
Active learning empowers machine learning algorithms to become more strategic in their learning process. The core principle lies in enabling the algorithm to query and select informative data points from a vast pool of unlabeled data.
These chosen data points are then presented to a human annotator or an oracle (information source) for labeling. The labeled data is subsequently used to iteratively refine the model's performance.
This cyclical process of query selection, labeling, and retraining allows the model to focus on the most critical data points, ultimately achieving better performance with a significantly smaller labeled dataset compared to passive learning.
Passive Learning vs. Active Learning: A Comparison
Traditional supervised learning, also known as passive learning, follows a straightforward approach. A fixed dataset, meticulously labeled beforehand, is fed into the learning algorithm. The algorithm passively processes this data to learn the underlying patterns and relationships.
While this method is widely used, it suffers from a major drawback: dependence on large amounts of labeled data. Labeling data can be a cumbersome, time-consuming, and sometimes expensive task. Here's a table summarizing the key differences:
This becomes a significant bottleneck when dealing with complex datasets or scenarios where acquiring labels is challenging.
Active learning, on the other hand, addresses this limitation by strategically selecting the most informative data points for labeling.
Why use active learning?
The traditional approach to supervised learning often faces a significant hurdle: the requirement for vast amounts of labeled data. Manually labeling data can be a painstaking and expensive process, especially for complex tasks or when dealing with sensitive data.
This is where active learning steps in, offering a compelling alternative for data-scarce scenarios. Here's a closer look at the key benefits of using active learning:
Reduced Labeling Cost
Active learning's core strength lies in its ability to significantly decrease the amount of labeled data needed to train a robust machine learning model. This is achieved by the algorithm's capability to strategically select the most informative data points from a large pool of unlabeled data.
These chosen data points are then presented for labeling, focusing human effort on the most critical pieces of information. By prioritizing the most impactful data, active learning can dramatically reduce the overall labeling cost, making it particularly attractive for scenarios where labeling is expensive or requires specialized expertise.
Improved Model Performance with Fewer Labeled Examples
Beyond reducing labeling costs, active learning can also lead to potentially better model performance compared to traditional passive learning methods. This advantage stems from the algorithm's ability to identify and focus on the most informative data points.
These data points often lie in areas of high uncertainty or near decision boundaries, where the model can benefit the most from additional information.
By strategically incorporating these informative points into the training process, active learning algorithms can achieve higher accuracy and generalization capabilities with a smaller set of labeled data points compared to passive learning approaches that rely on random sampling.
Theoretical Foundations for Improved Performance
The theoretical underpinnings of active learning's potential for improved performance lie in the concept of query complexity. Query complexity refers to the minimum number of labeled data points required by an algorithm to achieve a desired level of accuracy.
Active learning strategies, by focusing on informative data points, can demonstrably lower the query complexity of a model, leading to better performance with fewer labeled examples.
Active Learning: A Scalable Solution for Large Datasets
In the age of big data, where datasets can be massive and labeling all data points becomes impractical, active learning offers a scalable solution.
By selecting only the most informative data for labeling, active learning allows efficient training of models even on large datasets. This makes it particularly valuable for domains where data acquisition is easy but labeling remains a bottleneck.
How does active learning work?
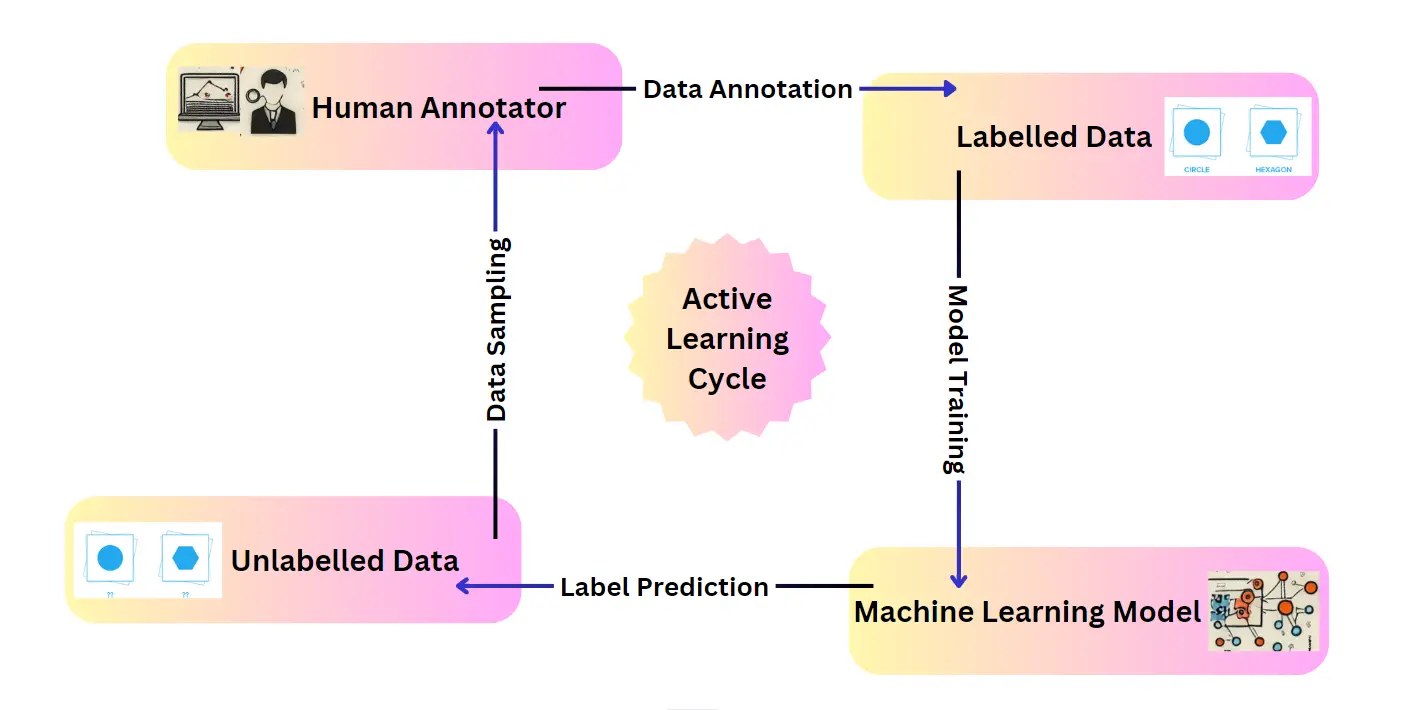
Active learning operates through an iterative cycle that strategically incorporates human expertise or informative data points to enhance the model's learning process. Here's a detailed breakdown of this workflow:
Step 1: Initialization: Seeding the Learning Process
The first step involves establishing a foundation for the learning algorithm. This entails acquiring a small, yet representative, set of labeled data points. This initial dataset serves as the seed for the learning process and provides the model with a basic understanding of the underlying relationships within the data.
The size and quality of this initial dataset can significantly impact the effectiveness of active learning, as it guides the initial learning direction.
Step 2: Model Training: Building the Foundation
Once the initial labeled data is prepared, the algorithm leverages it to train a preliminary machine-learning model. This model can be any suitable supervised learning algorithm, such as a decision tree, support vector machine, or neural network.
The training process allows the model to learn patterns and relationships present in the labeled data.
Step 3: Query Selection: The Art of Choosing Informative Data
Here's where active learning deviates from traditional approaches. After the initial training, the algorithm doesn't passively wait for more labeled data. Instead, it actively participates in the data selection process.
This core aspect of active learning involves employing a query selection strategy to identify the most informative data points from the vast pool of unlabeled data. These strategies aim to select data points that will have the most significant impact on the model's learning progress.
There are several popular query selection techniques, each with its own strengths and weaknesses. Here are a few examples:
Uncertainty Sampling: This strategy prioritizes data points for which the model has the lowest confidence in its predictions. These uncertain points hold the most potential for improvement and can significantly enhance the model's learning when labeled.
Margin Sampling: This approach focuses on data points closest to the decision boundary between different classes. By labeling these points, the model can refine its understanding of the separation between classes and improve its classification accuracy.
Query by Committee: When dealing with ensemble learning models, this strategy selects data points where multiple models within the committee disagree on the prediction.
These disagreements often represent areas of confusion, and labeling such points can help the ensemble learn a more robust model.
Step 4: Data Acquisition: The Labeling Process
Once the query selection strategy identifies the most informative data points, the algorithm retrieves them from the unlabeled pool. These chosen data points are then presented to a human annotator or an oracle (information source) for labeling.
The oracle can be a domain expert or a more general labeling service, depending on the specific task and data complexity.
Step 5: Model Retraining: Integrating New Knowledge
The newly acquired labeled data points are incorporated back into the training process. The model is then retrained on the combined dataset, which now includes the informative points chosen by the query selection strategy.
This retraining step allows the model to leverage the new information and refine its understanding of the data distribution.
Step 6: Iteration and Improvement: A Continuous Learning Cycle
The active learning process follows a cyclical pattern. After retraining, the algorithm repeats steps 3 through 5. It employs the updated model to select new informative data points, acquires labels for them, and retrains the model again.
This iterative process continues until a stopping criterion is met, such as achieving a desired level of model performance or exhausting a labeling budget.
Through this iterative cycle of active selection, labeling, and retraining, the active learning algorithm progressively refines its knowledge and improves its performance.
By focusing on the most informative data points, active learning achieves significant gains in model performance while requiring a substantially smaller amount of labeled data compared to traditional passive learning approaches.
Active Learning Query Selection Strategies
The heart of active learning lies in its ability to strategically select the most informative data points for labeling. This selection process, driven by a query selection strategy, plays a crucial role in maximizing the learning efficiency of the model. Here's a detailed exploration of some popular active learning query selection strategies:
Uncertainty Sampling: Focusing on the ambiguous
Uncertainty sampling prioritizes data points where the model has the lowest confidence in its predictions. These points often lie in areas with high ambiguity or near decision boundaries, where the model struggles to distinguish between different classes, as shown in the image below.
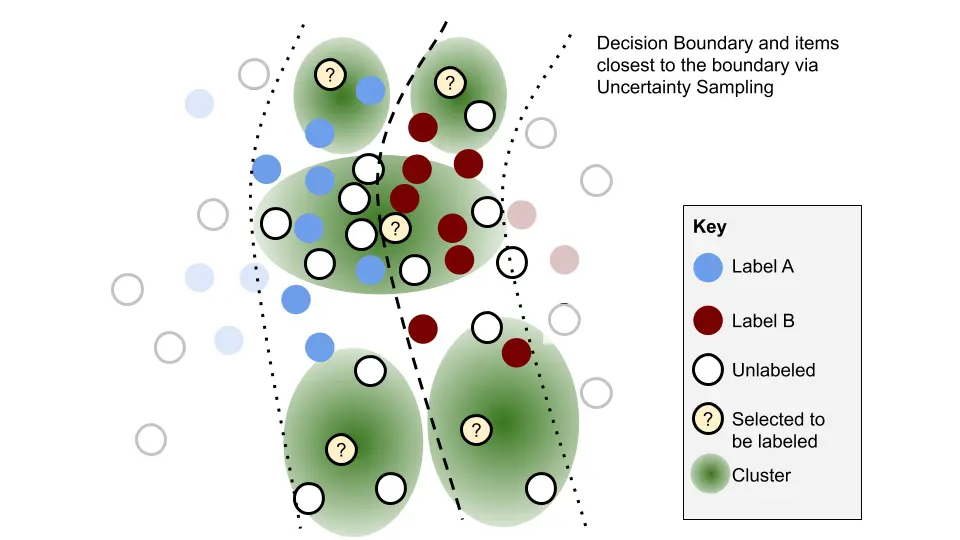
By selecting such data points for labeling, the model gains valuable information that significantly reduces its uncertainty in these regions. This strategy is particularly effective for classification tasks where the model outputs probabilities for each class.
Data points with the lowest predicted probability for the most likely class are prime candidates for uncertainty sampling.
Margin Sampling: Refining the Decision Boundary
Margin sampling focuses on data points closest to the decision boundary between different classes, as shown in the image below. These points represent challenging cases where the model has difficulty differentiating between classes.
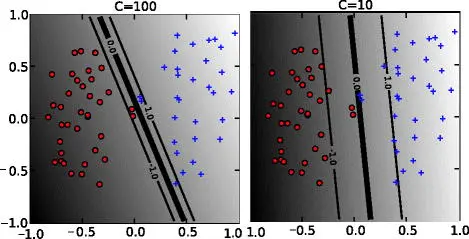
By acquiring labels for such data points, the model can refine its understanding of the separation between classes and improve its classification accuracy.
This strategy is particularly useful for tasks with well-defined class boundaries, such as image classification, where the goal is to distinguish between different objects in an image.
Query by Committee: Leveraging Ensemble Disagreement
Query by committee is a powerful strategy for active learning with ensemble models, which combine predictions from multiple individual models. This approach identifies data points where the models within the committee disagree on the prediction.
These disagreements often highlight areas of confusion or complex decision-making boundaries. By labeling such points, the ensemble can learn from its own inconsistencies and improve its overall performance.
This strategy can be computationally expensive due to the need to maintain and query an ensemble of models, but it can be highly effective in achieving robust performance. Here you can explore more (Link).
Diversity Sampling: Exploring the Data Landscape
Diversity sampling aims to select data points that are most dissimilar to the existing labeled data. This strategy ensures that the model is not biased towards certain regions of the data space and explores a wider variety of data points.
This can be particularly beneficial for tasks with high-dimensional data or complex distributions. By incorporating diverse data points, the model can learn a more generalizable representation of the underlying patterns.
One way to implement diversity sampling is to select data points furthest away from the existing labeled data points in terms of some distance metric.
Pool-Based Sampling: Balancing Exploration and Exploitation
Pool-based sampling strategies combine elements of uncertainty and diversity sampling. These approaches maintain a pool of candidate data points and employ a scoring mechanism that considers both the uncertainty of the model's prediction on a specific point and the diversity of that point relative to the existing labeled data.
By incorporating both factors, pool-based sampling aims to achieve a balance between exploration (discovering new information) and exploitation (refining the model on informative points).
Challenges of Active Learning
While active learning offers a compelling approach to machine learning with limited labeled data, it's not without its challenges. Here's a closer look at some of the key hurdles to consider when implementing active learning:
Selection Bias and Oracle dependency
The effectiveness of active learning hinges heavily on the chosen query selection strategy. A poorly designed strategy can lead to selection bias, where the model consistently chooses certain types of data points while neglecting others.
This can create gaps in the model's knowledge and hinder its ability to generalize effectively. Additionally, active learning often relies on an oracle (information source) for labeling the selected data points.
The quality and consistency of the oracle's labels significantly impact the model's performance. Errors or biases introduced by the oracle can propagate through the learning process.
Computational Cost of Query Selection
Active learning algorithms often involve complex calculations, particularly when dealing with large datasets or sophisticated query selection strategies. These calculations can be computationally expensive, especially when compared to the simpler approach of passive learning with random sampling.
This computational overhead can become a bottleneck for real-time applications or scenarios with limited resources.
Initial Labeled Data Requirements
While active learning aims to reduce the overall amount of labeled data needed, it still requires a seed set of labeled data to initialize the learning process. The quality and representativeness of this initial data significantly impact the effectiveness of active learning.
Insufficient or poorly chosen initial data can lead the model down the wrong path and hinder its ability to learn effectively.
Active Learning Doesn't Guarantee Better Performance
Active learning is a powerful tool, but it doesn't guarantee superior performance in all scenarios. The effectiveness of active learning depends heavily on the specific task, the data characteristics, and the chosen query selection strategy.
In some cases, well-designed passive learning approaches with a sufficient amount of labeled data might outperform active learning techniques.
Challenges in Integrating with Existing Systems
Integrating active learning algorithms into existing machine learning pipelines can be challenging. The iterative nature of active learning, with continuous data selection and retraining, might require modifications to existing workflows and infrastructure.
Additionally, effectively monitoring and evaluating the performance of active learning systems can be complex compared to traditional passive learning approaches.
Security and Privacy Concerns
Active learning often involves human intervention for data labeling. This raises security and privacy concerns, especially when dealing with sensitive data. Ensuring proper access control mechanisms and data anonymization techniques becomes crucial when implementing active learning in such scenarios.
Applications of Active Learning
Active learning isn't just a theoretical concept; it's a powerful tool driving innovation across various domains. By strategically selecting the most informative data points for labeling, active learning empowers machine learning models to achieve impressive results with less data.
This section delves into some real-world applications where active learning shines:
Construction Site Safety
Imagine equipping drones with image recognition capabilities to monitor construction sites for safety hazards. Active learning can be particularly useful in this scenario.
Limited Training Data: Initially, the dataset might be limited, containing images of common safety hazards like exposed wires or missing guardrails.
Active Querying: The model can use uncertainty sampling to identify ambiguous situations in drone footage. For instance, it might query a human expert on blurry images or scenes with cluttered backgrounds where it's unsure about a potential hazard.
Focused Learning: By focusing on these uncertain cases, the model can learn to identify a wider range of safety hazards with less data, improving overall safety monitoring on construction sites.
Medical Imaging
Active learning can play a crucial role in medical imaging analysis, such as classifying tumors in X-ray or MRI scans.
Expert Bottleneck: Radiologists are often overwhelmed by the sheer volume of scans they need to analyze.
Prioritizing Scans: Active learning can help prioritize scans that are most informative for diagnosis. For instance, the model might query a radiologist for scans with ambiguous features that could be cancerous or benign.
Reduced Workload: By focusing on these critical cases, active learning can reduce the radiologist's workload while still achieving high diagnostic accuracy, leading to faster and more efficient patient care.
Underwater Fish Identification
Active learning can be a valuable tool for marine biologists studying underwater ecosystems.
Limited Visibility: Underwater environments can be challenging for traditional image recognition due to limited visibility and variations in lighting.
Targeted Image Selection: Active learning can help select the most informative images for labeling by experts, such as those containing rare or difficult-to-identify fish species.
Expanding Knowledge: By focusing on these informative images, the model can learn to identify a wider variety of fish species with a smaller dataset of labeled images, contributing to a better understanding of underwater biodiversity.
Fruit Disease Detection
Active learning can be applied in agriculture to automate the detection of fruit diseases.
Early Intervention: Rapidly identifying diseases like blight or rot is crucial for preventing crop losses.
Focusing on Uncertain Cases: The model can use active learning to prioritize images of fruits with unclear signs of disease, querying human experts for confirmation.
Improved Accuracy: By focusing on these uncertain cases, the model can learn to distinguish between healthy and diseased fruits with higher accuracy, enabling farmers to take early action and optimize crop yields.
Conclusion
Active learning fundamentally changes the paradigm of machine learning by enabling algorithms to strategically select informative data for labeling.
This targeted approach offers significant advantages; it can dramatically reduce the amount of labeled data required to train a model, potentially leading to better performance compared to traditional passive learning methods.
However, active learning is not without its challenges. The effectiveness of this approach hinges on the quality of the initial labeled data and the design of the query selection strategy. Selection bias and oracle dependence can significantly impact the learning process.
Additionally, the computational overhead of query selection and the challenges of integrating active learning with existing systems require careful consideration.
Despite these limitations, active learning remains a powerful tool for applications where labeled data is scarce and achieving high performance with minimal resources is critical.
FAQ
1. What is active learning, and how does it differ from passive learning?
Active learning is a machine learning technique where the algorithm itself selects the data it wants to label from a pool of unlabeled data. This contrasts with passive learning, where a pre-defined, static set of labeled data is used for training. Active learning focuses on the most informative data points, potentially leading to better model performance with less labeled data.
2. Why is active learning useful?
Active learning is particularly valuable when labeling data is expensive or time-consuming. By focusing on the most informative data points, active learning significantly reduces the overall labeling effort required to train a robust machine learning model. Additionally, active learning can potentially improve model performance compared to traditional methods by prioritizing informative data for learning.
3. How does active learning work?
Active learning follows an iterative cycle. It starts with a small set of labeled data used to train an initial model. The model then employs a query selection strategy to choose the most informative data points from the unlabeled pool. These chosen points are labeled (by a human or information source) and incorporated back into the training process, refining the model's knowledge. This cycle continues until a stopping criterion is met, such as achieving desired performance or exhausting a labeling budget.
4. What are some challenges associated with active learning?
Active learning can be susceptible to selection bias if the query selection strategy is not well-designed. Additionally, the quality and consistency of the labels provided by the oracle (human annotator or information source) can significantly impact the model's performance. Other challenges include the computational cost of query selection, the need for a good initial labeled dataset, and the complexity of integrating active learning into existing systems.
References
- A Survey on Active Learning: State-of-the-Art, Practical Challenges and Research Directions(Link)

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
