

5 Best Tools for LLM Fine-Tuning in 2024


Introduction
Language Model Model (LLM) fine-tuning tools play a crucial role in optimizing Large Language Models (LLMs) for various natural language processing tasks.
In this blog, we'll learn about five leading tools – Labellerr, Kili, Label Studio, Databricks Lakehouse, and Labelbox; each offering unique features and approaches to enhance the fine-tuning process.
Whether you're a machine learning enthusiast or a professional looking to boost the performance of your LLMs, read this full blog to learn about the capabilities, advantages, and distinctive features of these tools.
1. Labellerr

Labellerr's LLM Fine-Tuning Tool emerges as an advanced and efficient platform, specifically designed to assist machine learning teams in setting up the Large Language Model (LLM) fine-tuning process seamlessly.
With Labellerr's versatile and customizable workflow, ML teams can expedite the preparation of high-quality training data for LLM fine-tuning in a matter of hours.
The tool offers a range of features aimed at optimizing the fine-tuning process, making it a smart, simple, and fast solution.
Key Features of Labellerr's LLM Fine-Tuning Tool:
1. Custom Workflow Setup
Tailored Annotation Tasks: Labellerr enables the creation of custom annotation tasks, ensuring the labeling process aligns with the specific requirements of LLM fine-tuning, such as text classification, named entity recognition, and semantic text similarity.
2. Multi-Format Suppor
Versatility Across Data Types: Labellerr supports various data types, including text, images, audio, and video.
This adaptability is particularly valuable for LLMs engaged in multi-modal tasks that involve different types of data.
3. Collaborative Annotation for Efficiency
Team Collaboration: Labellerr's collaborative annotation capabilities, especially in the Enterprise version, facilitate multiple annotators working on the same dataset.
This collaborative feature streamlines the annotation process, distributes the workload, and ensures consistency in annotations.
4. Quality Control Tools
Ensuring Annotation Precision: Labellerr provides features for quality control, including annotation history and disagreement analysis.
These tools contribute to maintaining the accuracy and quality of annotations, crucial for the success of the LLM fine-tuning process.
5. Integration with Machine Learning Models
Active Learning Workflows: Labellerr can be seamlessly integrated with machine learning models, allowing for active learning workflows.
This means leveraging LLMs for pre-annotation, followed by human correction, enhancing the efficiency of the annotation process, and improving fine-tuning results.
Labellerr's LLM Fine-Tuning Tool positions itself as an all-in-one platform that empowers machine learning teams to efficiently prepare high-quality datasets for the fine-tuning of Large Language Models.
With its user-friendly design and a focus on customization and collaboration, Labellerr offers a valuable solution for unlocking the full potential of LLMs in the evolving landscape of natural language processing and understanding.
2. Kili

Kili's LLM Fine-Tuning Tool is a comprehensive and user-friendly solution for individuals and enterprises seeking to enhance the performance of their Language Model Models (LLMs).
The platform offers a one-stop-shop experience, addressing five crucial elements for successful fine-tuning: clear evaluation, high-quality data labeling, feedback conversion, seamless LLM integration, and expert annotator access.
One of Kili's notable strengths lies in its approach to clear evaluation.
Assessing LLMs on generative tasks can be challenging, but Kili addresses this by allowing users to establish custom evaluation criteria.
This includes factors such as following instructions, creativity, reasoning, and factuality.
The platform combines automated LLM assessments with human reviews, ensuring both scalability and precision in the evaluation process.
High-quality data labeling is a cornerstone of effective fine-tuning, and Kili's platform excels in this aspect.
It caters to the diverse needs of fine-tuning projects, covering tasks such as classification, ranking, and transcription, as well as handling dialogue utterances.
Advanced quality assurance (QA) workflows, along with QA scripts and error detection in machine learning datasets, contribute to ensuring top-notch data annotation.
Kili Technology recognizes the value of user feedback in improving LLMs but acknowledges its limitations.
Kili employs an advanced filtering system to overcome noise and information scarcity.
This enables users to swiftly identify significant conversations and target annotation efforts efficiently, converting user insights into actionable training data.

Seamless integration with leading LLMs is another key feature of Kili's platform.
The elimination of unnecessary 'glue' code streamlines the process, allowing users to natively use a Copilot LLM-powered system for annotation.
Additionally, plug-and-play integrations with market-leading LLMs, such as GPT, simplify the fine-tuning process.
The importance of expert annotator access is emphasized by Kili, recognizing that fine-tuning LLMs requires both industry expertise and professional annotators.
The platform's approach involves handpicking labelers with specific industry-relevant knowledge, ensuring high-quality standards, and delivering labeled datasets swiftly, often within days.
With positive user testimonials highlighting its user-friendly interface and efficient tools, Kili's LLM Fine-Tuning Tool emerges as a leader in the field of data labeling and fine-tuning for Language Model Models.
The platform's all-in-one solution addresses the complexities of the fine-tuning process, making it a valuable resource for individuals and enterprises aiming to optimize the performance of their LLMs.
Key Features and Advantages
1. Clear Evaluation for Effective Fine-Tuning
Custom Evaluation Criteria: Users can establish criteria such as following instructions, creativity, reasoning, and factuality.
Automated LLM Assessments: Kili combines automated assessments with human reviews for both scalability and precision.
2. High-Quality Data Labeling
Diverse Task Handling: Kili's platform covers a mix of tasks, including classification, ranking, transcription, and dialogue utterances.
Advanced QA Workflows: Users can set up advanced QA workflows, implement QA scripts, and detect errors in machine learning datasets.
3. Feedback Conversion for Actionable Insights
Advanced Filtering System: Kili overcomes noise and information scarcity in user feedback through an advanced filtering system.
Efficient Targeting: Users can swiftly identify significant conversations, converting user insights into actionable training data.
4. Seamless Integration with Leading LLMs
Native Copilot LLM-Powered System: Users can natively use a Copilot LLM-powered system for annotation.
Plug-and-Play Integrations: Kili offers plug-and-play integrations with market-leading LLMs like GPT, eliminating unnecessary 'glue' code.
5. Expert Annotator Access for Industry-Relevant Excellence
Qualified Data Labelers: Kili provides qualified annotators with industry-specific expertise.
Handpicked Labelers: Annotators are handpicked to ensure high-quality standards, delivering labeled datasets swiftly, often within days.
6. Positive User Testimonials
User-Friendly Interface: Testimonials highlight Kili's user-friendly platform and easy navigation.
Efficient Tools: Users praise the efficiency of Kili's tools for data labeling and LLM fine-tuning.
3. Label Studio
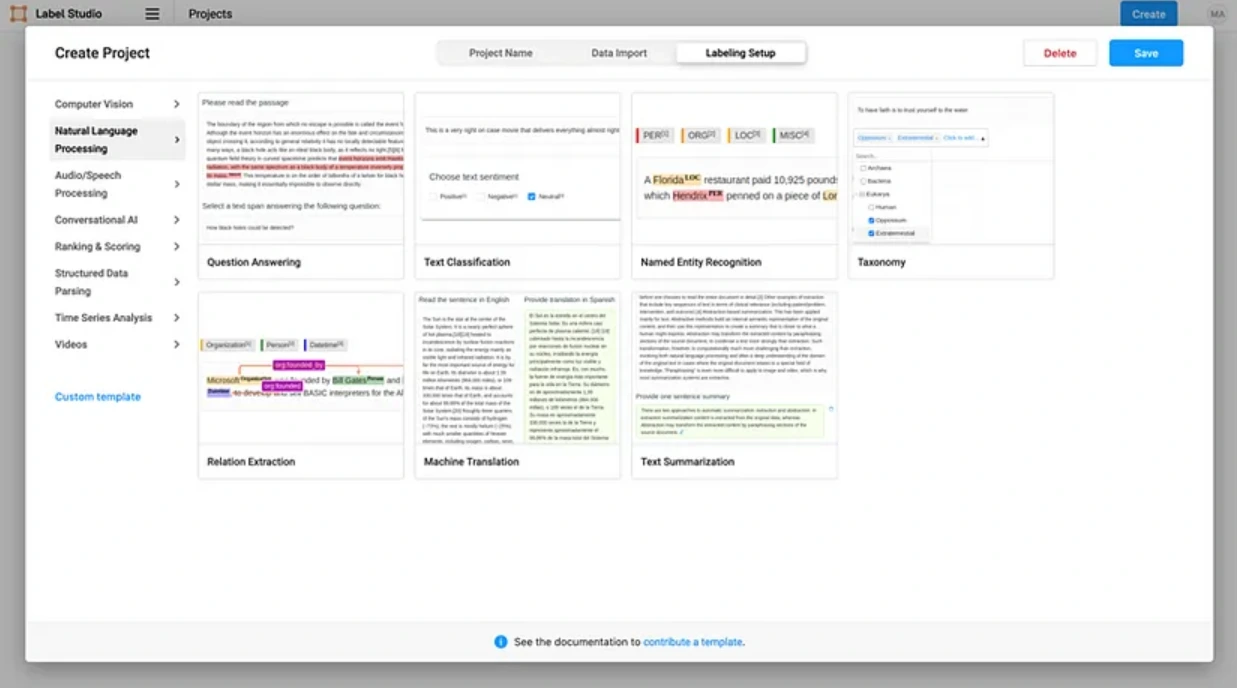
Label Studio's LLM Fine-Tuning Tool is a versatile and powerful data annotation platform specifically designed to enhance the process of fine-tuning Large Language Models (LLMs).
This tool plays a crucial role in preparing the data essential for refining LLMs by offering a range of features tailored to the intricacies of language model optimization.
With Label Studio, users can create customized annotation tasks, allowing for the precise labeling of data relevant to the specific requirements of LLM fine-tuning, including tasks such as text classification, named entity recognition, and semantic text similarity.
The tool's multi-format support is particularly advantageous, accommodating various data types such as text, images, audio, and video, aligning with the diverse needs of LLMs engaged in multi-modal tasks.
Furthermore, collaborative annotation capabilities streamline teamwork, ensuring multiple annotators can efficiently work on the same dataset, facilitating workload distribution, and maintaining consistency in annotations.
Label Studio's quality control features, including annotation history and disagreement analysis, contribute to the accuracy and reliability of annotations, which are pivotal for successful fine-tuning.
Additionally, the tool's seamless integration with machine learning models enables active learning workflows, where LLMs can be utilized for pre-annotation, followed by human correction, enhancing the overall efficiency of the annotation process and ultimately improving fine-tuning outcomes.
In essence, Label Studio's LLM Fine-Tuning Tool empowers users to prepare high-quality, task-specific datasets, unlocking the full potential of Large Language Models.
Label Studio's Role in Optimizing LLM Fine-Tuning
1. Custom Data Annotation Tasks:
Tailored Annotation: Label Studio allows the creation of custom annotation tasks specific to fine-tuning LLMs, accommodating needs such as text classification, named entity recognition, or semantic text similarity.
2. Versatile Multi-Format Support:
Adaptability Across Data Types: Label Studio supports diverse data types, including text, images, audio, and video, catering to the multi-modal nature of LLM tasks involving different data formats.
3. Collaborative Annotation Capabilities:
Enhanced Teamwork: Label Studio Enterprise facilitates collaborative annotation, streamlining the efforts of multiple annotators on the same dataset.
This collaborative feature aids in workload distribution and ensures consistency in annotations, crucial for preparing large datasets for LLM fine-tuning.
4. Quality Control Features:
Ensuring Annotation Precision: Label Studio Enterprise provides tools for quality control, including annotation history and disagreement analysis.
These features contribute to maintaining the accuracy and quality of annotations, essential for the success of the fine-tuning process.
5. Seamless Integration with ML Models:
Active Learning Workflows: Label Studio seamlessly integrates with machine learning models, enabling active learning workflows.
Leveraging LLMs to pre-annotate data, followed by human correction, enhances the efficiency of the annotation process and contributes to improved fine-tuning results.
Label Studio emerges as a powerful tool for optimizing the fine-tuning process of Large Language Models.
Through tailored annotation tasks, versatile support for multiple data formats, collaborative annotation features, robust quality control, and integration with machine learning models, Label Studio empowers users to efficiently prepare high-quality datasets, unlocking the full potential of LLMs.
4. Labelbox

Labelbox's LLM Fine-Tuning Tool is a comprehensive solution designed to facilitate the fine-tuning process of Large Language Models (LLMs).
LLMs leverage deep learning techniques for tasks such as text recognition, classification, analysis, generation, and prediction, making them pivotal in natural language processing (NLP) applications like AI voice assistants, chatbots, translation, and sentiment analysis.
Labelbox's tool specifically targets the enhancement of LLMs by providing a structured framework for fine-tuning.
Key Features and Workflow
Customizable Ontology Setup
Define your relevant classification ontology aligned with your specific LLM use case, ensuring the model is tuned to understand and generate content specific to your domain.
Project Creation and Annotation in Labelbox Annotate
Create a project in Labelbox, matching the defined ontology for the data you want to classify with the LLM.
Utilize Labelbox Annotate to generate labeled training data, allowing for efficient and accurate annotation.
Iterative Model Runs
Leverage iterative model runs to rapidly fine-tune OpenAI's GPT-3 model. Labelbox supports the diagnosis of performance, identification of high-impact data, labeling of data, and creation of subsequent model runs for the next iteration of fine-tuning.
Google Colab Notebook Integration
The integration with Google Colab Notebook streamlines the process, allowing for the importation of necessary packages, including Open AI and Labelbox, directly within the notebook.
API keys connect to instances seamlessly.
Adaptive Training Data Generation
The tool guides users in generating training data based on the defined ontology.
This step is crucial for adapting GPT-3 to the specific use case, ensuring that the model captures nuances relevant to the targeted domain.
Cloud-Agnostic Platform
Labelbox's cloud-agnostic platform ensures compatibility with various model training environments and cloud service providers (CSPs).
The platform seamlessly connects to the model training environment, enhancing flexibility and accessibility.
Advantages of Labelbox LLM Fine-Tuning Tool
Time and Cost Efficiency
Leveraging a foundational model like GPT-3 as a starting point saves significant time and costs compared to training models from scratch.
Reinforcement Learning from Human Preferences (RLHP)
The tool provides a framework for incorporating RLHP, a key aspect in significantly improving the performance of large language models.
Iterative Improvement
The iterative workflow empowers users to continuously fine-tune the GPT-3 model based on real-world data priorities, ensuring ongoing improvement and adaptability.
Performance Evaluation
Labelbox Model allows users to measure the performance of the model, identify areas of weakness, and iteratively improve by feeding relevant data back into the fine-tuning process.
Catalog Integration for Priority Data
Utilizing Labelbox Catalog features, users can prioritize data that will have the highest impact on the next training iteration, enhancing the model's ability to address edge cases effectively.
Labelbox's LLM Fine-Tuning Tool combines flexibility, efficiency, and iterative improvement, providing a structured approach for optimizing large language models in diverse NLP applications.
The integration with Google Colab Notebook and the cloud-agnostic platform further enhances the user experience, making it a valuable resource for machine learning teams seeking to fine-tune LLMs for their specific use cases.
5. Databricks Lakehouse
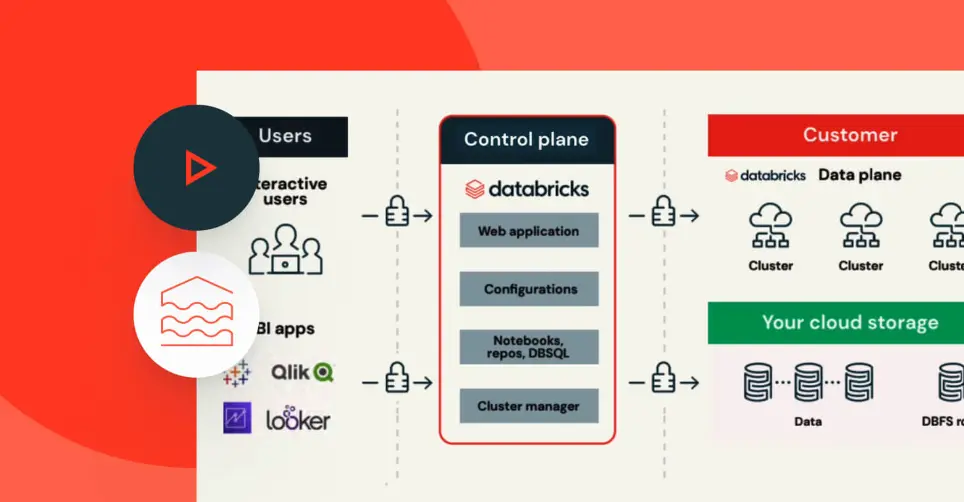
Databricks Lakehouse serves as a comprehensive platform for fine-tuning LLMs, with a focus on distributed training and real-time serving endpoints.
Key Features
1. Ray AIR Integration
Utilizes Ray AIR Runtime for distributed fine-tuning of LLMs, enabling efficient scaling across multiple nodes.
Offers integration with Spark data frames and leverages Hugging Face for data loading.
2. Model Tuning with RayTune
Allows for model hyperparameter tuning using RayTune, an integrated hyperparameter tuning tool within the Ray framework.
Distributed fine-tuning ensures optimal model performance for specific use cases.
3. MLFlow Integration for Model Tracking
Integrates with MLFlow for model version tracking and logging.
MLFlow's Transformer Flavor is utilized, providing a standardized format for storing models and their checkpoints.
4. Real-Time Model Endpoints
Enables the deployment of LLMs with real-time serving endpoints on Databricks.
Supports both CPU and GPU serving options, with upcoming features for optimized serving of large LLMs.
5. Efficient Batch Scoring with Ray
Demonstrates efficient batch scoring using Ray BatchPredictor, suitable for distributing scoring across instances with GPUs.
6. Low-Latency Model Serving Endpoints:
Databricks Model Serving Endpoints are introduced, offering low-latency and managed services for ML deployments.
GPU serving options are available, with upcoming features like optimized serving for large LLMs.
Advantages
1. Unified Framework
Ray AIR acts as a unifying framework, seamlessly connecting and orchestrating various tools, including Spark, Hugging Face, and MLFlow.
2. Distributed Scalability
Leverages distributed computing capabilities for both training and inference, ensuring efficient scaling of LLMs across clusters.
3. Flexible Model Tuning
Provides flexibility in model hyperparameter tuning through RayTune, adapting models to specific performance requirements.
4. MLFlow for Model Management
MLFlow integration allows for comprehensive model versioning, tracking, and logging, enhancing model management capabilities.
5. Real-Time Serving
Real-time serving endpoints facilitate the deployment of fine-tuned LLMs for immediate use in applications, reducing latency.
6. Support for Large Models
Addresses challenges related to GPU memory constraints, offering solutions and recommendations for optimizing resources.
Conclusion
The world of fine-tuning Large Language Models (LLMs) is evolving rapidly, and the blog has provided insights into five leading tools—Labellerr, Kili, Label Studio, Labelbox, and Databricks Lakehouse.
Each tool offers unique features and approaches to optimize the fine-tuning process, catering to the diverse needs of machine learning teams.
Labellerr stands out with its customizable workflow and integration capabilities, while Kili emphasizes clear evaluation and expert annotator access.
Label Studio offers a versatile platform with collaborative annotation features, Labelbox focuses on a structured fine-tuning framework, and Databricks Lakehouse excels in distributed training and real-time serving.
Whether you're a machine learning enthusiast or a professional seeking efficient solutions, exploring these tools can empower you to unlock the full potential of LLMs in natural language processing tasks.
Frequently Asked Questions
1. What is LLM fine-tuning?
LLM fine-tuning is like giving extra training to really smart computer models called Large Language Models (LLMs).
These models are already good at understanding and generating human-like language, but fine-tuning helps make them even better for specific tasks.
Imagine these models as students, and fine-tuning is like giving them extra practice on certain topics to make sure they excel in those areas.
It's a way to customize and boost their skills, making them more helpful in understanding and working with different kinds of language-based tasks.
2. How to fine-tune large language models (LLMs)?
Fine-tuning Large Language Models (LLMs) involves training an already pre-trained model on a specific dataset to make it more specialized for particular tasks. Here's a simplified step-by-step guide:
Choose a Pre-trained Model: Start with a pre-trained LLM. Popular ones include GPT-3, BERT, or others, depending on your needs.
Prepare Your Data: Gather a dataset that is relevant to your task. For example, if you're working on text classification or language understanding, collect a dataset with examples that match what you want the model to do.
Customize the Model: Adjust the pre-trained model for your specific task. This involves updating the model's weights using your dataset. You might need to modify certain parameters or layers to make it suitable for your task.
Fine-tune the Model: Train the modified model on your dataset. This involves running your data through the model, adjusting its internal workings based on the differences between its predictions and the correct answers in your dataset.
Evaluate Performance: Check how well your fine-tuned model performs on a separate set of data that it hasn't seen before. This helps ensure it's actually learning and improving.
Iterate if Necessary: Depending on the performance, you might need to go back, make adjustments, and fine-tune again. It's often an iterative process to achieve the best results.
Remember, the key is to strike a balance between using the general knowledge from the pre-training and adapting the model to your specific needs through fine-tuning.
3. Do you need memory for LLM fine-tuning?
Yes, memory is an important consideration when fine-tuning Large Language Models (LLMs).
The size of LLMs, such as GPT-3 or BERT, can be substantial, and the fine-tuning process requires memory to store and process the model's parameters, training data, and other relevant information.
Additionally, the size of your dataset, batch size, and the complexity of the model architecture can impact the memory requirements.
When working with large models, especially on GPUs, you need to ensure that your hardware has enough memory to accommodate both the model and the training data.
Insufficient memory can lead to out-of-memory errors or significantly slow down the training process. It's essential to check and optimize the memory usage during the fine-tuning process to ensure a smooth and efficient training experience.
Book our demo with one of our product specialist
Book a Demo